Generative AI third call for evidence: accuracy of training data and model outputs
This consultation sets out the ICO’s emerging thinking on generative AI development and use. It should not be interpreted as indication that any particular form of data processing discussed below is legally compliant.
This post is part of the ICO’s consultation series on generative AI. This third call focuses on how the accuracy principle applies to the outputs of generative AI models, and the impact that the accuracy of training data has on the output. We provide a summary of the analysis we have undertaken and the policy position we want to consult on.
You can respond to this call for evidence using the survey, or by emailing us.
The background
Data protection accuracy and statistical accuracy
Accuracy is a principle of data protection law. This legal principle requires organisations to ensure that the personal data they process is “accurate and, where necessary, kept up to date”. It also requires organisations to take “every reasonable step … to ensure that personal data that are inaccurate, having regard to the purposes for which they are processed, are erased or rectified without delay”. 1
This call for evidence focuses on the data protection concept of accuracy, ie whether personal data about someone is correct and up to date. This interpretation of accuracy differs from other uses of the word, such as the way that accuracy can sometimes be used by AI engineers in statistical modelling to refer to the comparison between the output of an AI system against the correctly labelled test data. We use the terms:
- ‘accuracy’ to refer to the accuracy principle of data protection law; and
- ‘statistical accuracy’ to refer to the accuracy of an AI system itself.
Personal data does not always have to be accurate
Personal data does not need to be kept up to date in all circumstances. Whether the data needs to be accurate depends on the purpose of processing: in some cases, it is appropriate to process information which is out of date (eg historical records) or not factually accurate (eg opinions).
Additionally, as the ICO’s Guidance on AI and Data Protection clearly sets out, 2 the accuracy principle does not mean that the outputs of generative AI models need to be 100% statistically accurate. The level of statistical accuracy which is appropriate depends on the way in which the model will be used, with high statistical accuracy needed for models which are used to make decisions about people. In this context, eg, models used to triage customer queries would need to maintain higher accuracy than models used to help develop ideas for video games storylines.
The impact of inaccuracy
Applying data protection accuracy principle in practice prevents false information being disseminated about people, and ensures that decisions about people are not made based on wrong information.
For generative AI models, both developers and deployers must consider the impact that training data has on the outputs, but also how the outputs will be used. If inaccurate training data contributes to inaccurate outputs, and the outputs have consequences for individuals, then it is likely that the developer and the deployer are not complying with the accuracy principle.
For example, if users wrongly rely on generative AI models to provide factually accurate information, there can be negative impacts such as reputational damage, financial harms and spread of misinformation. 3
Data protection law’s accuracy principle is closely linked to the right of rectification, which is a right that people have under the law to ask for their data to be corrected. The analysis in this document does not cover the right to rectification, but a future call for evidence will focus on people’s information rights in the context of generative AI development and use.
In more detail – ICO guidance on accuracy
Our analysis
Should the outputs of generative AI models be accurate?
This question can only be answered by first considering what a specific application based on a generative AI model is used for. Once the organisation deploying the model has established the purpose for it, and ensured with the developer that the model is appropriate for that purpose, it can then decide whether the purpose requires accurate outputs. For example:
- A model used to help game designers develop story lines does not necessarily need accurate outputs. The model output could provide storyline ideas in which invented facts are associated with real people; but
- A model used by an organisation to summarise customer complaints must have accurate outputs in order to achieve its purpose. This purpose requires both statistical accuracy (the summary needs to be a good reflection of the documents it is based on) and data protection accuracy (output must contain correct information about the customer).
Organisations developing and using generative AI models which have a purely creative purpose are unlikely to need to ensure that the outputs are accurate as their first priority. The more a generative AI model is used to make decisions about people, or is relied on by its users as a source of information rather than inspiration, the more that accuracy should be a central principle in the design and testing of the model.
The link between purpose and accuracy
The specific purpose for which a generative AI model will be used is what determines whether the outputs need to be accurate. 4 Therefore, it is of paramount importance that there is clear communication between the developers, deployers and end-users of models to ensure that the final application of the model is appropriate for its level of accuracy.
If a model is not sufficiently statistically accurate, because the purpose that the developer envisaged for it does not necessarily require accuracy, we would expect developers to put in place technical and organisational controls to ensure that it is not used for purposes which require accuracy. This could involve, for example, contractual requirements limiting types of usage in customer contracts with deployers or analysis of customer usage (when the model is accessed through an API).
Developers should also assess and communicate the risk and impact of so-called “hallucinations”, ie incorrect and unexpected outputs. These can occur due to the probabilistic nature of generative AI models. If controls to assess and communicate the likelihood and impact of inaccuracy are not in place, users may wrongly rely on generative AI tools to provide factually accurate information that it cannot actually provide.
Communication about and monitoring of appropriate use cases is particularly important when an application based on the generative AI is used by individuals in consumer-facing services. In these cases, we believe organisations who make the application available to people would need to carefully consider and ensure the model is not used by people in a way which is inappropriate for the level of accuracy that the developer knows it to have.
This could include:
- Providing clear information about the statistical accuracy of the application, and easily understandable information about appropriate usage; 5
- Monitoring user-generated content, either by analysing the user query data or by monitoring outputs publicly shared by users;
- User engagement research, to validate whether the information provided is understandable and followed by users; and
- Labelling the outputs as generated by AI, or not factually accurate. This could be done for example by embedding metadata in the output or making imperceptible alterations to it to record its origin (sometimes referred to as “watermarking” and “data provenance”);
- Providing information about the reliability of the output, for example through the use of confidence scores. The reliability of a generative AI model’s output could be assessed by reference to reliable sources of information, using retrieval augmentation generation techniques. 6
Developers need to set out clear expectations for users, whether individuals or organisations, on the accuracy of the output. They should also carry out research on whether users are interacting with the model in a way which is consistent with those expectations. This will give the ICO, and individual users, assurance that developers and deployers are taking responsibility for ensuring that the usage is appropriate for the level of accuracy that the model can provide.
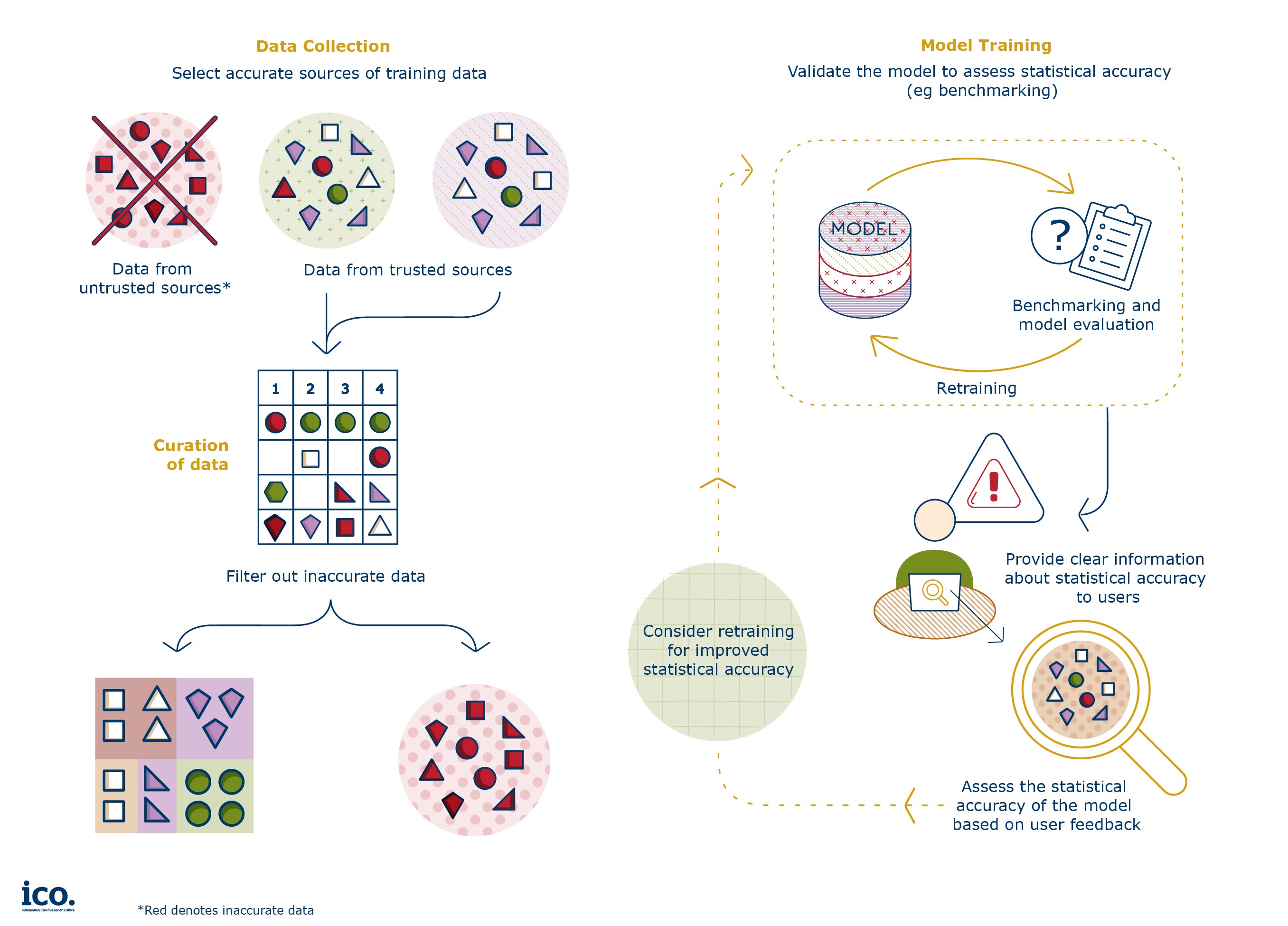
Figure 1, showing the stages at which developers and deployers can ensure compliance with the data protection principle of accuracy of the Generative AI model.
Applications based on generative AI models can have many uses even if they are not intended to produce accurate information about people. The key point is that such applications are clearly positioned as either not being accurate or as having clear and explained limitations in their accuracy where necessary, to avoid misuse or overreliance on their results, resulting in harms to individuals.
How does training data affect the accuracy of the output?
If a generative AI model will be used for a purpose which requires accurate outputs, the developer will need to consider to what extent the accuracy of the training data will impact that.
The developer can improve its compliance with its accuracy responsibilities in two ways:
- In many cases, the developer will know and control how the generative AI model will be deployed. To ensure it complies with the accuracy principle under data protection, the developer should curate the training data accordingly to ensure sufficient accuracy for the purpose.
- In some cases, the developer may not envisage all the ways in which the model may be deployed. If the generative AI model they develop does not provide accurate outputs, the developer should clearly, transparently and concisely communicate the accuracy limitations to deployers and end users, to meet the developer’s data protection accuracy obligations.
In terms of the first point, we understand that developers sometimes select training data from social media and user forums, and weight it according to the amount of engagement the content has had. While content that has been highly engaged with may assist in training the model to produce engaging content, we are interested in evidence about how this can be reconciled with the legal requirement for accuracy. In particular, we are keen to hear from organisations about how to assess, measure and document the relationship between inaccurate training data and inaccurate model outputs.
This is relevant not only to a data protection context and the ICO’s remit, but to the wider debate about how generative AI capabilities can lead to or exacerbate broader issues, such as misinformation.
In more detail – ICO guidance on transparency and information rights
Conclusion
Our expectation is that developers have a good understanding of how accurate the training data they are using to develop generative AI models is. Developers should:
- Know whether the training data is made up of accurate, factual and up to date information, historical information, inferences, opinions, or even AI-generated information relating to individuals;
- Understand and document the impact that the accuracy of the training data has on the generative AI model outputs;
- Consider whether the statistical accuracy of the generative AI model output is sufficient for the purpose for which the model is used and how that impacts on data protection accuracy; and
- Clearly, transparently and concisely communicate steps 1-3 to deployers and end users, to ensure that the lack of accuracy at the training stage does not result in negative impacts on individuals at the deployment phase.
Deployers of generative AI are responsible for clear communication with end users, and we would expect them to:
- Consider how a potential lack of accurate training data and outputs could impact individuals and mitigate those risks ahead of deployment (eg, restrictions on user queries, output filters);
- Provide clear information about the statistical accuracy of the application and its intended use; and
- Monitor how the application is used to inform and, if necessary, improve the information provided to the public and restrictions on the use of the application.
1 Article 5(1)(d) of the UK GDPR
2 What do we need to know about accuracy and statistical accuracy?
3 For example: ChatGPT: Mayor starts legal bid over false bribery claim - BBC News, Lawyer Used ChatGPT In Court—And Cited Fake Cases. A Judge Is Considering Sanctions and Company worker in Hong Kong pays out £20m in deepfake video call scam
4 For more analysis on the purpose of processing in the context of generative AI, see our second Call for Evidence
5 For guidance on explainability in AI, see: Explaining decisions made with AI
6 See, for example: What is retrieval-augmented generation?