Generative AI first call for evidence: The lawful basis for web scraping to train generative AI models
This consultation sets out the ICO’s emerging thinking on generative AI development and use. It should not be interpreted as indication that any particular form of data processing discussed below is legally compliant.
This post is part of the ICO’s consultation series on generative AI. This call focuses on the lawful basis for scraping data from the web or processing web-scraped data to train generative AI models. We provide a summary of the analysis we have undertaken and the policy position we want to consult on.
You can respond to this call for evidence using the survey or by emailing us at [email protected]. Please share your thoughts with us before the consultation deadline of 1 March 2024.
The background
Collecting training data as part of the first stage of the generative AI lifecycle
Developing a generative AI model involves several stages. The first steps are collecting and pre-processing the training data. The data is then used to train the base model. The base model is then fine-tuned for deployment in a specific context and its performance is evaluated. Regular feedback is provided for model improvement post-deployment.
Figure 1: An indicative model development lifecycle. Some of the later steps may be interchangeable and iterative depending on the context.
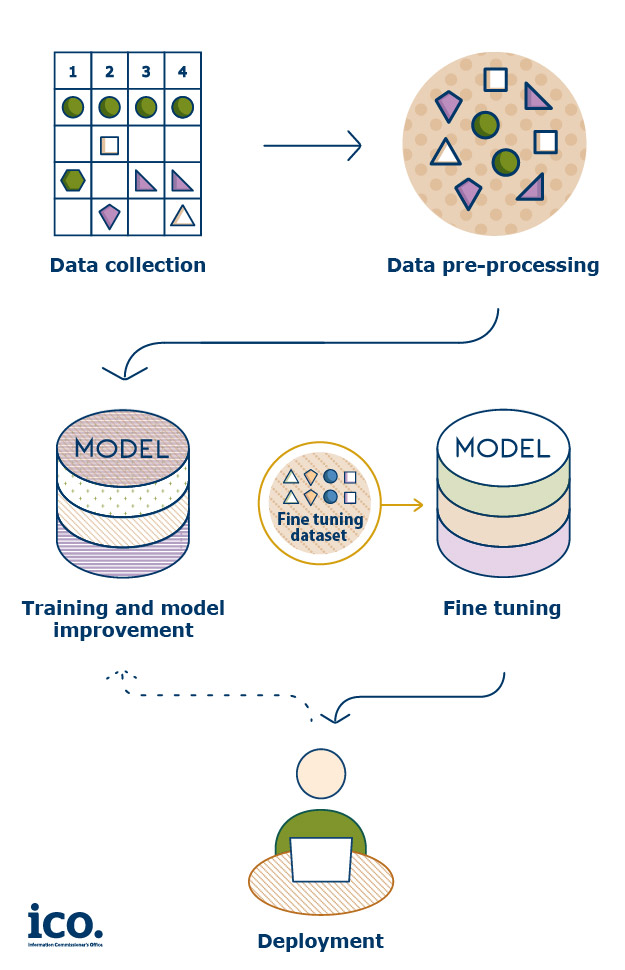
Training data for generative AI: what is it and where does it come from?
Most developers of generative AI rely on publicly accessible sources for their training data. Developers either collect training data directly through web scraping, indirectly from another organisation that have web-scraped data themselves, or by a mix of both approaches. In either approach, developers need to ensure the collection of the personal data they process to train models complies with data protection.
What is web scraping?
Web scraping involves the use of automated software to ‘crawl’ web pages, gather, copy and/or extract information from those pages, and store that information (e.g. in a database) for further use. The information can be anything on a website – images, videos, text, contact details, etc.
Information scraped from internet environments such as blogs, social media, forum discussions, product reviews and personal websites may contain personal data that individuals have placed there. It is important to note the internet also contains information that was not placed there by the person to whom it relates (eg discussion forums, leaked information etc).
What are the possible lawful bases for collecting training data?
As part of complying with the lawfulness principle of data protection, developers need to ensure their processing:
(a) is not in breach of any laws; and
(b) has a valid lawful basis under UK GDPR.
The first aspect (a) will not be met if the scraping of personal data infringes other legislation outside of data protection such as intellectual property or contract law.
To address point (b) and determine a lawful basis, generative AI developers need to consider the six lawful bases set out in Article 6(1) UK GDPR. Based on current practices, five of the six lawful bases are unlikely to be available for training generative AI on web-scraped data.
For this reason, this call for evidence focuses on the legitimate interests lawful basis (Article 6(1)(f) of the UK GDPR), which may apply in some circumstances. To meet the legitimate interests basis, the controller must pass the ‘three-part’ test 1 and demonstrate that:
- the purpose of the processing is legitimate;
- the processing is necessary for that purpose; and
- the individual’s interests do not override the interest being pursued.
In more detail – ICO guidance on legitimate interest:
Our analysis
Is legitimate interests a valid lawful basis for training generative AI models on web-scraped data?
Legitimate interests can be a valid lawful basis for training generative AI models on web-scraped data, but only when the model’s developer can ensure they pass the three-part test. In order to do that they can undertake a variety of actions, which we will explore below.
Purpose test: is there a valid interest?
As controllers for the generative AI model training, developers need to identify a legitimate interest for processing the web-scraped personal data in the first place. Despite the many potential downstream uses of a model, they need to frame the interest in a specific, rather than open-ended way, based on what information they can have access to at the time of collecting the training data.
The developer’s interest could be the business interest in developing a model and deploying it for commercial gain, either on their own platform or bringing it into the market for third parties to procure. There may also be wider societal interests related to the applications that the models could potentially power – but in order to rely on these the developer must be able to evidence the model’s specific purpose and use.
The key question is this: if you don’t know what your model is going to be used for, how can you ensure its downstream use will respect data protection and people’s rights and freedoms?
Developers who rely on broad societal interests need to ensure that those interests are actually being realised rather than assumed, by applying appropriate controls and monitoring measures on the use of the generative AI models they build on web-scraped data.
Necessity test: is web scraping necessary given the purpose?
The necessity test is a factual assessment that asks whether the processing is necessary to achieve the interest identified in the purpose test. The ICO’s understanding is that currently, most generative AI training is only possible using the volume of data obtained though large-scale scraping.
Even though future technological developments may provide novel solutions and alternatives, currently there is little evidence that generative AI could be developed with smaller, proprietary databases. We welcome views on this point.
Balancing test: do individuals’ rights override the interest of the generative AI developer?
If a controller has established there is a legitimate purpose is using web-scraped data for generative AI training, and the processing is necessary for that purpose, the final step is to assess the impact on individuals and identify whether the interests, rights and freedoms of those individuals override those pursued by the controller or third parties.
Collecting data though web-scraping is an ‘invisible processing’ activity, where people are not aware their personal data is being processed in this way. This means people may lose control over how and what organisations process their personal data or become unable to exercise the information rights granted by UK data protection law. Invisible processing and AI related processing are both seen as high-risk activities that require a DPIA under ICO guidance.2
How do individuals’ interests play out in the balancing test?
There is a growing literature on the risks and harms of generative AI models. 3, 4 Individuals whose data is scraped for generative AI development can experience harm, either related to the collection of the training data or because of the use of the generative AI model. These harms can manifest in two ways:
- Upstream risks and harms: For example, people may lose of control over their personal data, 5 as they are not informed of its processing and therefore are prevented from exercising their information rights or evaluate the impact of that processing on them, including its fairness.
- Downstream risks and harms: For example, generative AI models can be used to generate inaccurate information about people 6 resulting in distress 7 , 8 or reputational harm, be used by hackers 9 deploying social engineering tactics to generate phishing emails 10 tailored to individuals or undertake other adversarial attacks 11.
Further reading
Risk mitigations to consider in the balancing test
There are a number of considerations that may help generative AI developers pass the third part of the legitimate interests test, relevant to both the development and deployment of a model.
The extent to which generative AI developers can mitigate downstream harms during deployment depends on the way in which the models are put into the market.
Generative AI models deployed by the initial developer
Where a generative AI model developer deploys the model on its own platform, the expectation is they can exercise complete control over how the generative AI model is used. If the developer relies on the public interest of the wider society for the first part of the test, in order to pass the entire test they should still be able to:
- control and evidence whether the generative AI model is actually used for the stated wider societal benefit;
- assess risks to individuals (both in advance during generative AI development and as part of ongoing monitoring post-deployment); and
- implement technical and organisational measures to mitigate risks to individuals.
Generative AI models deployed by a third-party (not the initial developer), through an API
Another route to generative AI model deployment is for the developer to make the model available via an API to a third-party. In this context, the third party does not have their own copy of the underlying generative AI model but can query it through the API, feeding into it their own data. This is sometimes referred to as a ‘closed-source’ approach.
In this case, the initial generative AI developer can seek to ensure that the third party’s deployment is in line with the legitimate interest identified at the generative AI training phase, by implementing technical (eg output filters, etc) and organisational controls over that specific deployment.
For example, API access can be used to limit queries (preventing those likely to result in risks or harms to individuals) and to monitor the use of the model. Contractual restrictions and measures could also be used to support this, with the developer legally limiting the ways in which the generative AI model can be used by its customers. We are interested in hearing more about mitigation measures and how their efficacy is evaluated and documented.
Generative AI models provided to third parties
If copies or extensive details (eg model weights, starting code, etc) of the underlying generative AI models are made available by the initial developer to third parties, developers are expected to have much less control over how the model will be used downstream. In these cases (sometimes referred to as an ‘open-source’ approach), customers typically run their own instance of the generative AI model.
Where the generative AI model has the capacity to be implemented in unlimited variety of downstream applications, its initial developers may not be able to restrict or monitor how the model is used and therefore its impact. This means they may have no way of knowing whether the potential broad societal interest identified at the initial training stage is being realised in practice. Additionally, where the third-party’s use of the model is unrestricted, articulating clearly and with precision the broad societal interest of developing the initial model could become extremely difficult, as the developer may not meaningfully know or monitor how the model will be used.
Contractual controls may mitigate this risk, though the developer would also need to evidence that any such controls are being complied with in practice"
Conclusion
Training generative AI models on web scraped data can be feasible if generative AI developers take their legal obligations seriously and can evidence and demonstrate this in practice.
Key to this is the effective consideration of the legitimate interest test. Developers using web scraped data to train generative AI models need to be able to:
- Evidence and identify a valid and clear interest.
- Consider the balancing test particularly carefully when they do not or cannot exercise meaningful control over the use of the model.
- Demonstrate how the interest they have identified will be realised, and how the risks to individuals will be meaningfully mitigated, including their access to their information rights.
1 What is the legitimate interests basis?
2 Examples of processing ‘likely to result in high risk’
3 Evaluating social and ethical risks from generative AI - Google DeepMind
4 Generating Harms: Generative AI’s Impact & Paths Forward – EPIC – Electronic Privacy Information Center
5 OpenAI, Google, and Meta used your data to build their AI systems - Vox
6 Six Risks Of Generative AI (forbes.com)
7 I felt numb – not sure what to do. How did deepfake images of me end up on a porn site? - Deepfake - The Guardian
8 Spanish prosecutor investigates if shared AI images of naked girls constitute a crime - Spain - The Guardian
9 AI: a new tool for cyber attackers — or defenders? - ft.com
10 ChatGPT tool could be abused by scammers and hackers - BBC News
11 The Cybersecurity Crisis of Artificial Intelligence: Unrestrained Adoption and Natural Language-Based Attacks