Generative AI second call for evidence: Purpose limitation in the generative AI lifecycle
This consultation sets out the ICO’s emerging thinking on generative AI development and use. It should not be interpreted as indication that any particular form of data processing discussed below is legally compliant.
This post is part of the ICO’s consultation series on generative AI. This second call focuses on how the data protection principle of purpose limitation should be applied at different stages in the generative AI lifecycle. We provide a summary of the analysis we have undertaken and the policy position we want to consult on.
You can respond to this call for evidence using the survey, or by emailing us at [email protected].
The background
A specified, explicit and legitimate purpose
The purpose limitation principle in data protection law requires organisations to be clear and open about why they are processing personal data, and to ensure that what they intend to do with it is in line with individuals’ reasonable expectations.
Purpose limitation requires organisations to have a clear purpose for processing any personal data before they start processing it. If they are not clear about why personal data is processed, it follows they will not be able to be clear with individuals.
This purpose must be legitimate, meaning that:
- there must a lawful basis for processing it; 1 and
- the purpose is not in breach of other laws, such as intellectual property or contract laws.
The purpose must also be specified and explicit: organisations need to be clear about why they are processing the personal data. Organisations must be clear about this both in their internal documentation and governance structures but also with the people to whom the personal data relates.
Different stages, different purposes
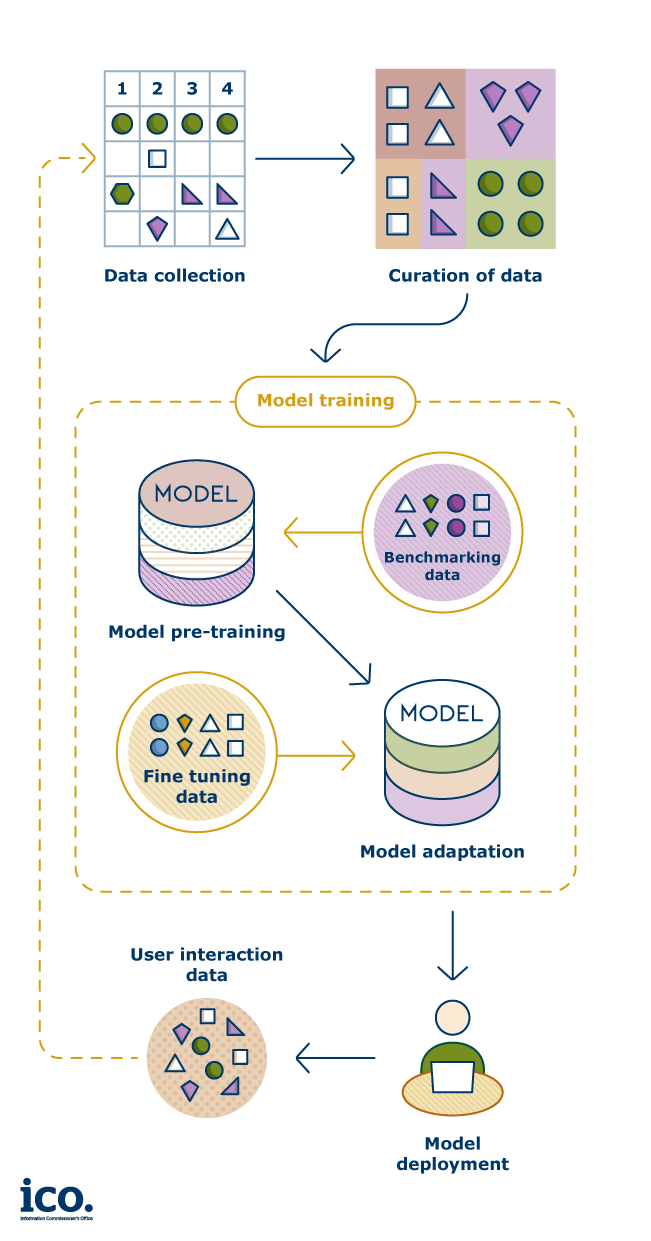
The generative AI model lifecycle involves several stages. Each stage may involve processing different types of personal data and for different purposes. Data protection considerations are relevant for any activity that involves processing personal data.
For example, the purpose of training a core model will require training data and test data, while the purpose of adapting the core model may require fine-tuning data from a third-party developing its own application.
Different organisations may have control over these different purposes (eg whether a model will be fine-tuned to power an application) helping delineate the boundaries of purposes.
Why is purpose limitation important?
Having a specified purpose in each stage will allow an organisation to appropriately understand the scope of each processing activity, evaluate its compliance with data protection and help them evidence that.
For example, a developer may collect training data and also train a generative AI model on that data. After model training, the developer may decide to develop an application with which to deploy the model to serve some business objective. It is essential that the organisation doing the model development and deployment understands and documents those two purposes separately.
Without appropriate separation of purposes, the developer cannot assess how they meet the other data protection principles, including whether:
- the data is necessary for the purpose (minimisation principle);
- the use of the data for that purpose is lawful (lawfulness principle);
- the purpose has been explained to the people the data relates to (transparency principle);
- the purpose falls within people’s reasonable expectations or it can be explained why any unexpected processing is justified (fairness principle); and
- whether the stated purpose aligns with the scope of the processing activity and the organisation’s ability to determine that scope.
In more detail – ICO guidance on purpose limitation
Our analysis
The compatibility of reusing training data
Training data can be expensive and difficult to collate, so developers may want to return to the same or an enriched training dataset and use it many times. If training data is reused in this way, for example to train two or more different models, the developers who are reusing the training data must consider whether the purpose of training a new model is compatible with the original purpose of collecting the training data.
A key factor to consider is what was the reasonable expectation of the individual whose data is being re-used at the moment its processing began. If the further processing is not compatible with the original purpose, the controller will need to establish a new, separate purpose.
This compatibility assessment may be easier for organisations that have a direct relationship with the individuals whose personal data the generative AI encodes during training.
Where the developer has no direct relationship with that individual, public messaging campaigns and prominent privacy information may help to increase the awareness of individuals, as well as safeguards (anonymisation or the use of privacy-enhancing technologies) to mitigate the possible negative consequences to individuals.
If the further processing is not compatible with the original purpose, the controller will need to establish a new, separate purpose.
In more detail – ICO guidance on compatibility assessments
One model, many purposes
A variety of generative AI-powered applications such as chatbots, image generators and virtual assistants can all rely on an underlying model that acts as their foundation. After the initial training of the generative AI model, an application is built based on it or a fine-tuned version of it, enabling its deployment in the real world.
This means that one core model can give rise to many different applications. For example, the same large language model could be used to produce an application to help with ideation, an application that answers customer emails, an application that generates legal contracts or even a general-purpose application that can ultimately be used for any of those tasks.
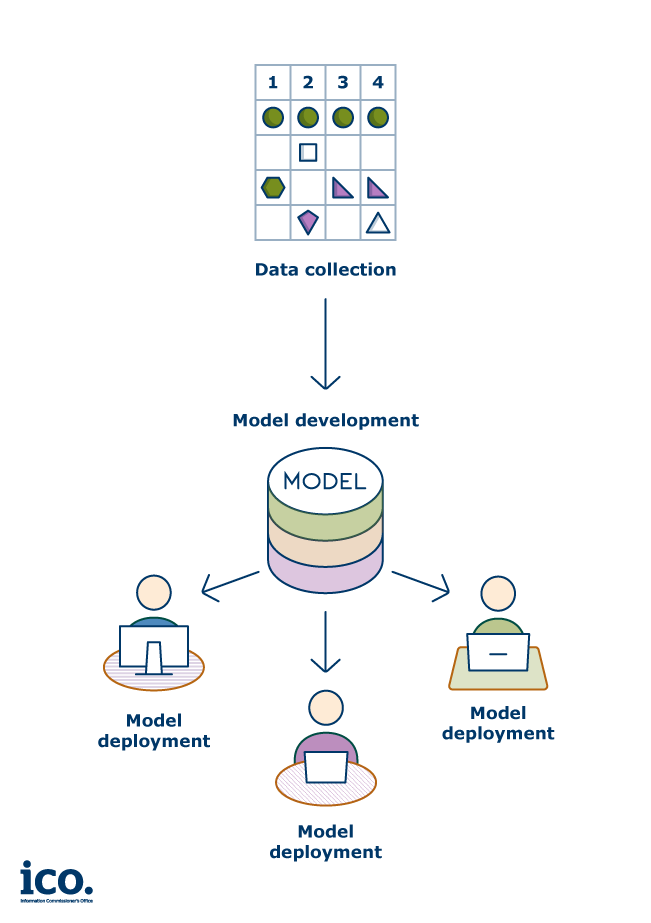
At the time the initial generative AI model is trained, the developer may already have the specific application or applications they want to build in mind. Alternatively, and in particular if the developer and the deployer are different organisations, the application may be specified only afterwards, once the core model is already in existence.
The two processing activities may be carried out by the same organisation, or by different ones. We understand that common industry practice includes the following scenarios:
- One organisation develops both the generative AI model, and the application built on top of it; 2
- One organisation develops the generative AI model, then provides it or a fined-tuned version of it to another organisation who then may develop an application that embeds it to serve its own business objectives; and
- One organisation develops the generative AI model, then develops an application based on the model for another organisation, following their instructions about the intended purpose for the product.
We consider that developing a generative AI model and developing an application based on such a model (fined-tuned or not) constitute different purposes under data protection law. This is in addition to the initial separate purpose that an organisation may pursue when collating repositories of web-scraped data.
Defining a purpose
The purpose must be detailed and specific enough so that all relevant parties have a clear understanding of why and how the personal data is used. These parties include:
(i) the organisation developing the model;
(ii) the people whose data is used to train it;
(iii) the people whose data is used during the deployment; and
(iv) the ICO.
Developers who rely on very broad purposes (eg “processing data for the purpose of developing a generative AI model”) are likely to have difficulties in explaining both internally and externally the specific processing activities that purpose covers. This is because, without a precise explanation of what the purposes are, it will be hard for the developer to demonstrate why particular types of personal data are needed, or how any legitimate interests balancing test is passed.
Defining a specific and clear purpose for each different processing is key to a data protection by design and by default approach.
Developers and deployers who consider the entire lifecycle of generative AI can assess what the purpose of each of the stages of the lifecycle is, and then go on to establish what personal data (if any) is needed for that purpose. A clearly defined purpose will also help developers and deployers to allocate controller and processor responsibility for the different stages of the lifecycle and explain that allocation of responsibility to people whose data is being processed.
We understand that purposes in the earlier stages of the generative AI lifecycle such as the initial data collection may be less easy to precisely define than those closer to the deployment end. The development of many generative AI models is open-ended, with a business goal of developing multi-functional, general-purpose models that will enable companies to scale at all verticals. Nevertheless, defining a purpose at the initial stages of the generative AI lifecycle involves considering what types of deployments the model could result in, and what functionality the model will have.
When developing an application based on the model, it will be easier to specify the purpose of that processing in more detail. Organisations developing applications based on generative AI models should consider what these applications will be used for, and what personal data processing is needed to develop it (eg, fine-tuning to ensure the model is trained for the task in the specific context which it will be deployed).
Conclusion
The power of generative AI models is partly due to the broad way in which they can be used. Despite the open-ended ambition of these models, developers need to give careful consideration to the purpose limitation requirements of data protection, to ensure that before they start processing, they can:
- Set out sufficiently specific, explicit and clear purposes of each different stage of the lifecycle; and
- Explain what personal data is processed in each stage, and why it is needed to meet the stated purpose.
Organisations will be better able to comply with data protection law and maintain public trust if they give careful consideration to the difference between developing the generative AI model, developing the application based on it, and are clear about what types of data are used and how in each case.
1 See the first call for evidence for more detail on the lawful basis: Generative AI first call for evidence: The lawful basis for web scraping to train generative AI models
2 The application through which the model is deployed can then be made available to other parties or made accessible through an API, as discussed in our first Call for Evidence.