Generative AI fourth call for evidence: engineering individual rights into generative AI models
This consultation sets out the ICO’s emerging thinking on generative AI development and use. It should not be interpreted as indication that any particular form of data processing discussed below is legally compliant.
This post is part of the ICO’s consultation series on generative AI. This fourth call focuses on individual rights - the information rights data protection confers to people over their personal information - and in particular in relation to the training and fine-tuning of generative AI. We provide a summary of the analysis we have undertaken and the policy positions we want to consult on.
You can respond to this call for evidence using the survey, or by emailing us. Please share your thoughts with us by 10 June 24.
The background
People’s rights over their information
Under data protection law, people have individual rights over their personal data. Organisations must enable the exercise of these rights.
These include the right:
- to be informed about whether their personal data is being processed;
- to access a copy of it;
- to have information about them rectified, if it is inaccurate; and
- not to be subject to solely automated decisions that have legal or similarly significant effects on them.
In some circumstances they also have the right:
- to have information about them deleted; and
- to restrict or stop the use of their information.
These rights apply wherever personal information is processed. In the context of generative AI, this means they apply to any personal data included in:
- the training data;
- data used for fine-tuning, including data from reinforcement learning from human feedback and benchmarking data;
- the outputs of the generative AI model; and
- user queries (eg when a data subject enters personal information via a prompt into the model).
Therefore, across the AI lifecycle organisations must have processes in place (including technical and organisational measures) to enable and record the exercise of people’s rights.
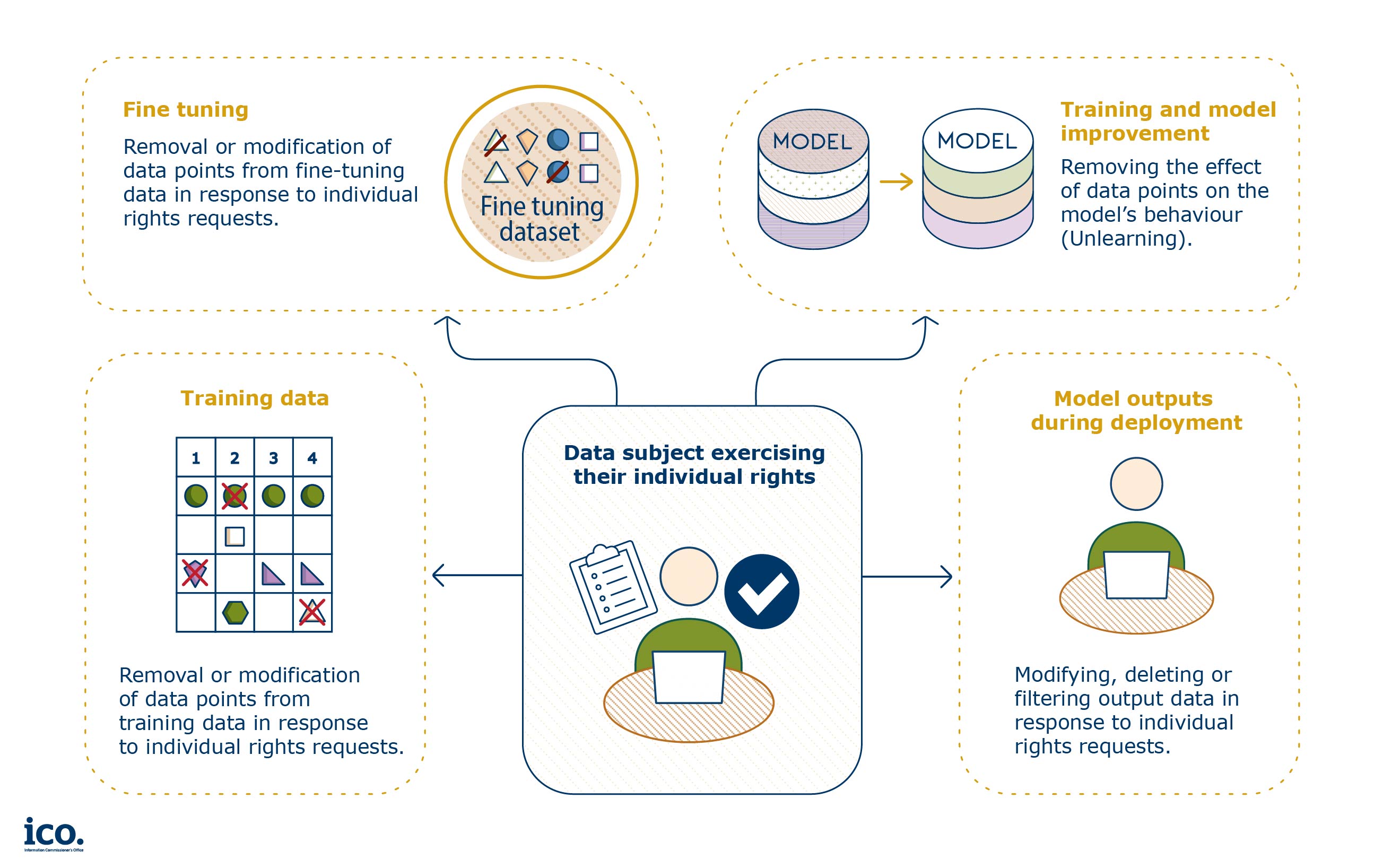
A text description of this image can be found here.
The ICO has produced guidance on our expectations around logging and responding to rights requests 1, a process that is the cornerstone of building public trust and accountability.
In more detail – ICO guidance on individual rights
The scope for this call for evidence
This call focuses on how organisations developing generative AI – including organisations fine-tuning generative AI models for their own deployment – enable people to exercise their rights:
- to be informed about whether their personal data is being processed;
- to access a copy of it;
- to have information about them deleted, where this applies; and
- to restrict or stop the use of their information, where this applies.
The call does not examine rights related to automated decision-making; for information on these see the “further reading” box below.
In more detail – ICO guidance on individual rights
Our analysis
Development stage
The right to be informed
Individual rights apply to the processing of personal data in all contexts, including when it is used to train and fine-tune generative AI models. Since individuals can only exercise these rights if they know their information is being processed, the right to be informed is a prerequisite for exercising other information rights.
Generative AI developers use a diverse range of datasets. Figure 2 illustrates indicative sources and types of data used for training and fine-tuning.
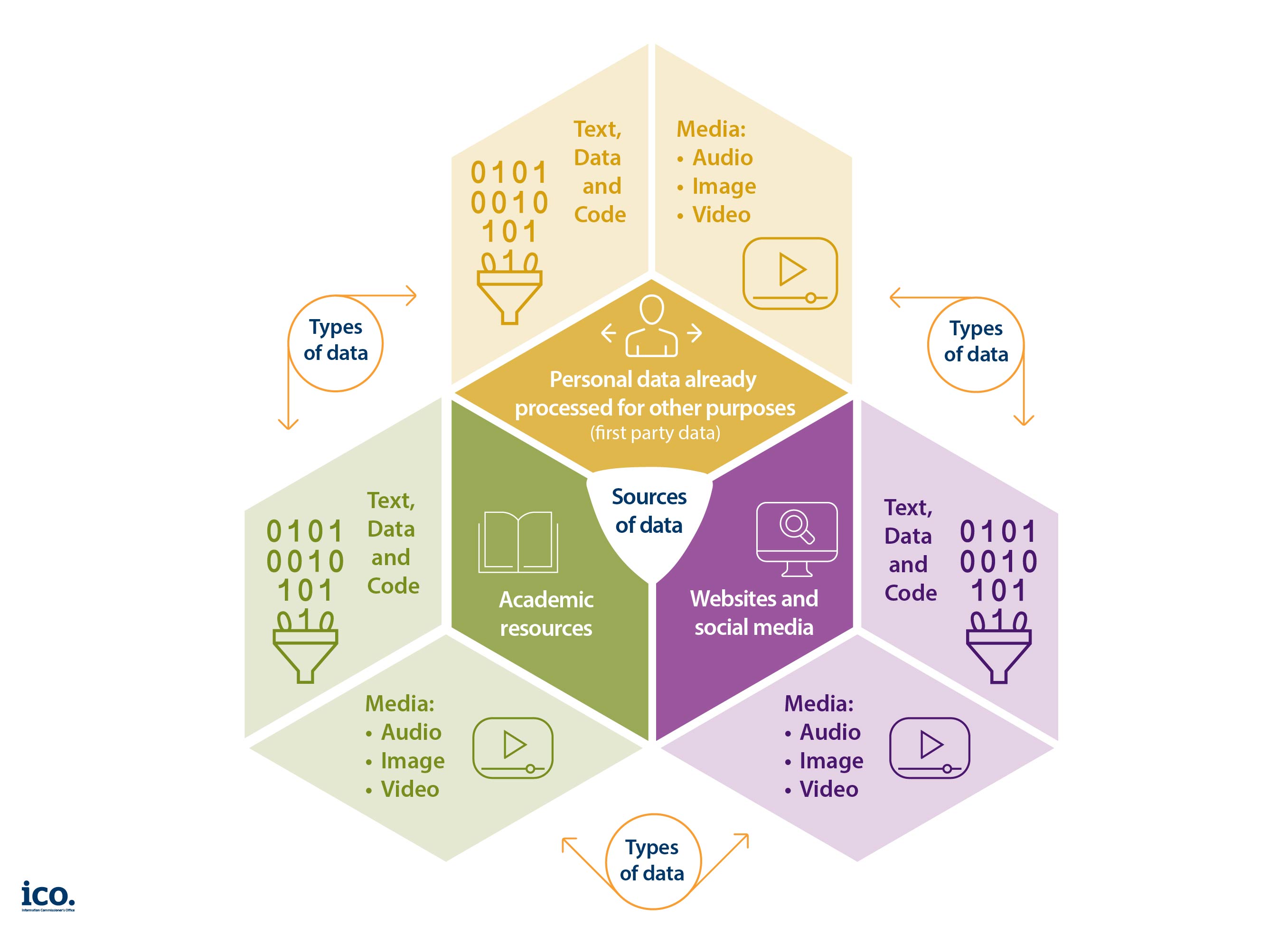
Where personal data is collected directly from individuals
Generative AI developers will often collect personal data from individuals directly. This may take place to support model training or fine-tuning, and may include data gathered after the model has been deployed (for example collection of prompts for ongoing model development). Where they do so, they must provide individuals with clear information about the use of this data and how they can exercise their rights, as described in Article 13 UK GDPR.
Generative AI developers may sometimes process personal data that has been supplied by their clients. For example, a bank may provide customer data to an LLM developer for them to fine-tune their model for a financial services context. Where the client collects data directly from individuals they must comply with Article 13 and be clear about the fact the data is used for AI training.
Where personal data is collected from other sources
Generative AI developers will typically collect personal data from sources other than individuals (for example, via web-scraping). In these cases the right to be informed still applies, as described in Article 14 UK GDPR.
In the context of Article 14, there are exceptions to the right to be informed, for example if it is impossible or would require disproportionate effort to provide the privacy information to each individual whose data has been collected. This is likely to be the case for web-scraped datasets that may relate to millions – if not billions – of individuals.
For web-scraped datasets, the processing of personal data to develop generative AI models is likely to be beyond people’s reasonable expectations at the time they provided data to a website. For example, someone writing a post in 2020 about a visit to their doctor won’t expect that data to be scraped in 2024 to train a generative AI model. In some cases, people will not even be aware of information that has been posted or leaked about them online.
Generative AI developers seeking to apply Article 14 exceptions still must take appropriate measures to protect individuals’ rights and freedoms, including by making privacy information publicly available. This includes:
- Publishing specific, accessible information on the sources, types and categories of personal data used to develop the model. Vague statements around data sources (eg just ‘publicly accessible information’) are unlikely to help individuals understand whether their personal data may be part of the training dataset or who the initial controller is likely to be.
- Publishing specific, accessible explanations of the purposes for which personal data is being processed (see our previous consultation on purpose limitation) and the lawful basis for the processing (see our previous consultation on lawful bases). This should be sufficient to enable individuals to have a meaningful understanding and clear expectations of what happens to their data. Where the lawful basis is legitimate interests, organisations must state the specific interests being pursued.
- Providing prominent, accessible mechanisms for individuals to exercise their rights, including the right of access and the rights to rectification, to erasure, to restriction of processing and to object to processing.
We invite views on what further measures generative AI developers should take to safeguard individuals’ rights and freedoms. For example, developers could apply privacy-enhancing technologies or other pseudonymisation techniques to limit the identifiability of the data being processed.
Resource or expense requirements should be factored into business decisions from the very start, in particular in light of the requirement to apply a data protection by design and by default approach that ensures data protection principles are implemented effectively – including transparency, fairness and accountability.
In more detail - ICO guidance
The right of access
People have a right of access to a copy of the personal data held about them. We expect developers to have accessible, clear, easy-to-use, documented and evidenced methods to facilitate and respond to these requests regardless of whether they relate to data used in training, fine-tuning or deployment.
If developers argue they are not able to respond to requests because they cannot identify individuals (in the training data or anywhere else), the law requires them to explain this to the individual who has made the request, and demonstrate why this is the case if possible. 2 The individual can then decide if they want to provide additional information for facilitating the identification as per Article 11(2).
In more detail – ICO guidance
Rights to erasure, to rectification, to restriction of processing and to object to processing
In certain circumstances, people have rights to object to the processing of their personal data, to restrict its processing and to obtain its rectification or erasure. Our guidance on individual rights explains when these apply.
When people want to exercise their right to object or to rectification, their requests should be addressed within one month (or three months if an extension is necessary) and in a verifiable manner. We would welcome evidence on how these requests are being respected in practice. We are keen to hear people’s experiences of exercising their rights to object or rectify their data.
Generative AI developers need to be able to apply these rights to the processing of all personal data, from the training data through to model outputs. This may be challenging as generative AI models present memorisation issues 3 which reflect the fact that during training these models do not just parse personal data like traditional software but retain its imprints (as they need to ‘learn’). This is one of the reasons they can unintentionally output sections of the training data they have ‘memorised’ without being explicitly asked.
Many developers use input and output filters to mitigate the risk that a generative AI model outputs personal data. Input filters are processing techniques that may be used to detect and amend specific user prompts, whereas output filters are processing techniques that may be used to detect and amend specific model outputs. We invite views on whether input and output filters are a sufficient mechanism for enacting people’s rights. We are interested in evidence of the efficacy of these measures 4 and are keen to hear about alternative approaches to suppressing or removing personal data from a trained generative AI model, in particular approaches such as “machine unlearning”. 5
Where groups of individuals exercise these rights (for example, a specific community of people), generative AI developers will also need to consider the implications for the fairness and statistical accuracy of the model itself and put mitigation measures in place. We invite views on what mitigation measures should be in place where groups of individuals exercise their rights. We are interested in receiving evidence on relevant approaches.
Deployment stage
A variety of organisations are involved in the generative AI supply chain, from organisations supplying datasets, to developers training models, to companies deploying them. This supply chain includes a variety of processing operations, from data collection to training, to producing inferences.
Despite this complexity, people's rights need to be respected throughout the AI lifecycle and supply chain, including during deployment. This relates to the data of people that were part of the original training dataset but also the personal data inputted into the live model after launch or any outputs that can constitute personal data.
Responsibility for fulfilling these rights lies with the organisations who are controllers or joint controllers for the different sets of operations. We will examine controllership in the generative AI supply chain as part of the fifth call for evidence in this series.
Conclusion
Most current generative AI models are trained on datasets containing personal data or process personal data in the deployment stage to generate outputs. Organisations developing or using these models have a legal duty to enable people to exercise their rights over the personal data involved.
Organisations developing or using generative AI models need to be able to:
- demonstrate they have a clear and effective process for enabling people to exercise their rights over personal data contained in the training, fine-tuning, and output data, but also the model itself.
- evidence how they are making sure data subjects have meaningful, concise and easily accessible information about their use of personal data; and
- clearly justify the use of any exemptions and demonstrate the measures taken to safeguard people’s interests, rights and freedoms.
We are calling for evidence on tested, verifiable and effective methods that organisations are developing or using to meet their legal obligations in this area, to support innovation and the protection of personal data in the development and use of generative AI.
3 The Flaw That Could Ruin Generative AI - The Atlantic
4 Researchers have already flagged the limitations of these approaches
5 One of the most established AI conferences, NeurIPS, and Google have launched machine unlearning ‘challenges’. For more see: A Survey of Machine Unlearning