Latest update
15 March 2023 - This is a new chapter with new content. This section is about data protection fairness considerations across the AI lifecycle, from problem formulation to decommissioning. It sets outs why fundamental aspects of building AI such as underlying assumptions, abstractions used to model a problem, the selection of target variables or the tendency to over-rely on quantifiable proxies may have an impact on fairness. This chapter also explains the different sources of bias that can lead to unfairness and possible mitigation measures. Technical terms are also explained in the updated glossary.
At a glance
This section is about data protection fairness considerations across the AI lifecycle, from problem formulation to decommissioning. It sets out potential sources of bias. For example, your choice of training data, or the historical bias embedded in the environment you choose to collect your data from. It also explains how fairness can be impacted by fundamental aspects of AI development. For example, the choice around what aspects of the real-world problem to include or omit from your decision-making process, or how you assume what you are trying to predict is linked to the data you process.
However, fairness for data protection is not the only concept of fairness you need to consider. There may be sector-specific concepts as well as obligations in relation to discrimination under the Equality Act. This guidance only covers data protection fairness.
Technical terms, such as reward function or regularisation, are explained in the glossary of the main guidance on AI and data protection.
Who is this section for?
This section is predominantly for AI engineers and key decision-makers in the development and use of AI products and services. It also provides useful foundational knowledge for data protection officers, risk managers, as well as information for the broader public around the processes or decisions that may lead to unfair outcomes in the context of AI and any mitigations.
In detail
- How to use this annex
- Project initiation and design
- Before you process personal data
- Data collection
- Data analysis and pre-processing
- Model development
- Model evaluation
- Deployment and monitoring
- Decommissioning or replacing an AI system
How to use this annex
Examining the different data protection fairness considerations across the AI lifecycle is not a linear process. You are likely to need to take an iterative approach, moving back and forth between different steps.
The AI lifecycle does not have a standardised format, so you should see the one we’ve used here as indicative. We divide the lifecycle into the following stages:
- Project initiation and design
- Before you process personal data
- Data collection and procurement
- Data analysis and pre-processing
- Model development
- Model evaluation
- Model deployment and monitoring
- Retiring or decommissioning
If you process personal data, you must consider the data protection principles across the AI lifecycle, not just at specific stages. For example, when you use AI to make solely automated decisions, you must consider an individual’s ability to understand and contest those decisions, throughout the lifecycle.
Organisational measures to help you comply with fairness include:
- adopting a data protection by design approach;
- conducting a DPIA; and
- ensuring appropriate governance measures around your deployment act as safeguards against unfairness.
The section on fairness in the main guidance on AI and data protection sets out some of these relevant approaches.
The technical approaches we set out in this annex are neither exhaustive nor a ‘silver bullet’. Determining which are appropriate will be a process of trial and error, particularly as techniques evolve and mature, or demonstrate limitations as they do so. For any technique you use, you should assess:
- whether it works as intended;
- how it interacts or influences your entire decision-making process;
- whether it reinforces or replicates unfair discrimination; and
- any detrimental unintended consequences that may arise (eg creating additional risks to privacy, data protection and fundamental rights).
The specific technical and organisational measures you need to adopt depend on the nature, scope, context, and purpose of your processing and the particular risks it poses. In any case, you should test the effectiveness of these measures at the design stage and detail:
- how the measures mitigate risks; and
- whether they introduce other risks, and steps you will take to manage these.
It is important to acknowledge that most of the technical approaches we set out in this section seek to address the risk of discrimination. You should remember that data protection’s fairness is broader than discrimination and can be too context-specific to be neatly addressed by technical approaches alone. Nevertheless, these technical approaches can help you.
If you are procuring AI as a service or off-the-shelf models, asking for documentation could assist you with your fairness compliance obligations as the controller for processing your customer data. This could include:
- information around the demographic groups a model was originally or continues to be trained on;
- what, if any, underlying bias has been detected or could emerge; or
- any algorithmic fairness testing that has already been conducted.
Further reading in ICO guidance
Outcome fairness (Explaining decisions made with AI)
1. Project initiation and design
Frame the problem, set out your goals, and map your objectives
At this stage in the lifecycle, you should:
- effectively frame the real-world problem you seek to solve via AI; and
- clearly articulate your objectives.
This is known as the problem formulation stage, where you translate a real-life problem into a mathematical or computable one that is amenable to data science. You should pay attention to fairness at this stage. This is because these first steps influence the decisions you take later, such as trade-offs or benchmarking during development and testing.
You should clearly set out the problem with detail and clarity.
This enables you to test the validity of how you frame the real-world problem and translate it into a computable one. For example, whether the prediction you are trying to make is:
- directly observable in the available data; or
- a construct you can only observe indirectly (eg are you directly measuring whether someone is a ‘good employee’ or are you just observing indirect indicators, such as performance reviews and sales?).
Depending on your context, you may optimise for more than one objective, tackling a multi-objective problem. For example, an organisation may decide to use AI as part of its recruitment strategy to sift job applications. The organisation can design the system to take into account multiple objectives. This could include minimising commuting time, mapping salary expectations to resources, maximising flexibility around working hours and other variables. If you clearly define and articulate the different objectives at this early stage, you are better placed to ensure that the impacts your system has are fair.
Examine the decision space
Problem formulation also involves evaluating the “decision space”. This refers to the set of actions that you make available to your decision-makers. When you consider using AI to tackle a complex issue, it is important to evaluate the effects of limiting the decision space to binary choices. This may lead to unfair outcomes, such as increased risk of making unfair decisions about individuals or groups.
Example
An organisation uses an AI system to approve or decline loans. If it limits the decision space to this binary choice, without considering the terms under which the loan is granted to different individuals, it may lead to unfair outcomes. For example, giving loans to vulnerable people under punitive conditions would make them unsustainable.
Certain types of decisions require a nuanced, case-by-case approach because of their socio-political impact, scale or legal implications. This is the context that Article 22 of the UK GDPR tries to capture. Not all problems can be effectively expressed via (or meaningfully solved by) algorithms that only reflect statistics and probabilities.
Problem formulation: what you assume, measure and infer
Problem formulation involves a concept known as the “construct space”. This involves using proxies, or “constructs”, for qualities that you cannot observe in the real world. For example, creditworthiness is a construct. This stage generally involves four aspects. These may introduce their own risks. For example:
- Abstraction reduces the complexity of a problem by filtering out irrelevant properties while preserving those necessary to solve it. As this implies a loss of information, you should ensure that you do not discard information that is critical to the solution or that can help you avoid unjustified adverse effects on individuals. One way of mitigating this risk is to consult additional expertise to improve your contextual knowledge.
- Assumptions relate to a series of decisions about interdependencies and causality that are taken as a given. For example, when you use a measurable, observable construct to represent an unmeasurable, unobservable property you assume an interdependency between the two. However, certain properties that are fundamental to answering your problem may not just be unmeasurable, but also unable to be represented by an unobservable property (or construct). This means that your model may be built on invalid assumptions that will impact the effects it has on individuals when you deploy it. This is why it is important to test and validate your assumptions at all stages.
- Target variables are what your model seeks to measure. Your choice of target variables can also have implications for whether or not your model’s outcomes are likely to be unfair. This can happen if the target variable is a proxy for protected characteristics (because it is correlated with them). Or, if it is measured less accurately for certain groups, reflecting measurement bias (see later section). For example, predictive policing models may rely on past arrest records which may be racially biased. You should therefore examine your target variable’s validity.
- Measurability bias is the tendency to over-rely on quantifiable proxies rather than qualitative ones. This can lead to omitting useful features from your model’s design, or embedding unwanted bias by using unreliable proxies just because they are easily available. Effective problem formulation is about ensuring what you plan to measure captures the nuance and context of the actual problem.
When you formulate the problem, you should also think about how a decision-support system will interact with human decision-makers and reviewers. This is because the system’s predictions may not be sufficient for them to make the most informed decision. How you formulate a problem and what limitations your formulation has may have an impact on how effective human oversight is in the final system. Humans need to be aware of these limitations.
Further reading outside this guidance
For more on target variables and their effects on fairness in the US context see ‘Big data's disparate impact’
For more on the link between the problem formulation stage and fairness see ‘Problem formulation and fairness’
Who are the impacted groups and individuals?
From a fairness perspective it is important that you are able to explain why your AI system is applied to specific groups of individuals and not others. This guidance refers to these as ‘impacted groups’.
You may intend to apply your model to particular groups. However, you must also consider whether your system may influence other groups indirectly. For example, an AI system managing childcare benefits does not only impact the claimants but the children under their custody as well.
Also, when thinking about impacted groups, you must consider the possibility that because of their different contexts not all individuals in the group will be impacted in the same way.
Engage with individuals your system affects
To ensure the development and deployment of your AI system is fair, you should engage with people with lived experience relevant to your use case or their representatives, such as trade unions. Article 35(9) of the UK GDPR states that organisations, depending on their context, must seek the views of individuals or their representatives on the intended processing as part of a DPIA. Lived experience testimonies may challenge the assumptions made during your problem formulation stage. But this can help you to manage costly downstream changes, as well as mitigating risk.
For example, this kind of input can help you identify and understand how marginalisation affects the groups your system may impact. In turn, this may lead to design changes during the development process which ensure your system has a better chance of delivering fair outcomes when you deploy it. Setting up a way to incorporate this feedback post-deployment, as part of your monitoring measures, aligns with data protection by design.
Further reading
For more information, read the subsection on culture, diversity and engagement with stakeholders in “How should we manage competing interests when assessing AI-related risks?”
You could adopt a participatory design approach
Independent domain expertise and lived experience testimony will help you identify and address fairness risks. This includes relative disadvantage and real-world societal biases that may otherwise appear in your datasets and consequently your AI outputs over time.
This approach is known as “participatory design” and is increasingly important to AI systems. It can include citizens’ juries, community engagement, focus groups or other methods. It is particularly important if AI systems are deployed rapidly across different contexts, creating risks for a system that may be fairness compliant in its country of origin to be non-compliant in the UK for instance.
Participatory design can also help you identify individuals’ reasonable expectations, by discussing available options with their representatives.
For engagement with impacted groups to be meaningful, they or their representatives need to know about:
- the possibilities and limitations of your AI system; and
- the risks inherent in the dynamic nature of the environments you deploy it in.
If you decide to adopt a participatory design approach, you should seek to validate your design choices with these stakeholders and reconcile any value conflicts or competing interests. You could also view participatory design as something you embed into your AI project lifecycle. This will help you refine your models based on actual experience over time.
Consult independent domain experts
Your organisation as a whole may not have the necessary knowledge of what marginalisation means in all possible contexts in which you may use your AI system. It is important that key decision-makers at management level acknowledge this. Seeking and incorporating advice from independent domain experts is good practice. Article 35(9) of the GDPR supports this approach.
Determining the relevant domain expertise depends on the circumstances in which you develop and deploy your AI system, along with the impacted groups it relates to.
Your senior decision-makers should invest appropriate resources and embed domain experts in the AI pipeline. This will make it easier to avoid unfairness downstream in the AI lifecycle as it will ensure your developers can draw on that expertise at various points of the production.
Additionally, decision-making processes that can lead to unfair outcomes can be sector specific. Depending on the context, multidisciplinary expertise from social sciences, such as sociology or ethnography, could be useful to understand how humans interact with AI systems on the ground.
Further reading outside this guidance
For more information on challenges AI developers face in identifying appropriate performance metrics and affected demographic groups see ‘Assessing the fairness of AI systems: AI practitioners’ processes, challenges, and needs for support’
2. Before you process personal data
You should determine and document your approach to bias and discrimination mitigation from the very beginning of any AI application lifecycle. You should take into account and put in place the appropriate safeguards, technical and organisational measures during the design and build phase.
Consider what algorithmic fairness approaches are appropriate for your use case
Your choice of algorithmic fairness metrics should relate to your context, objectives and what your distribution of outcomes should reflect. For example, in the case of granting a loan, if you chose equality of opportunity as the metric you test your system against. This would mean that someone’s chance of being predicted to repay their loan, given that they in fact will go on to repay it, is the same regardless of their group. Equalised odds, on the other hand, is even stricter. It also requires that someone’s chance of being incorrectly predicted to default on their loan, when they will in fact go on to repay it, is the same regardless of their group.
It is good practice to identify the algorithmic fairness approach you have chosen and why., Depending on the context, you may also be required to do so. Our guidance on outcome fairness can help you be transparent about it to individuals.
You can apply algorithmic fairness approaches at different stages of your lifecycle. You can undertake pre-processing bias mitigation, for example by removing examples from your training dataset that you suspect may lead to discrimination. You can seek to mitigate bias in-processing by changing the learning process of your model during training so it incorporates particular algorithmic fairness metrics. You can also modify the model after the initial training, at the post-processing stage.
In the real world algorithmic fairness metrics eventually relate to the distribution of resources or opportunities. However, ensuring fair outcomes is not always dependent on distributions. Instead, this may require you to consider more qualitative and contextual aspects, such as how human rights are affected or under what terms a job applicant is invited for an interview. At the same time, in certain circumstances unequal distribution may be justifiable. For example, it may be preferable to distribute aid ‘unequally’ in favour of those who need it most.
You should document and justify how you make decisions about distributing resources or opportunities. Algorithmic fairness metrics are not always mathematically compatible with each other. Therefore, you may not be able to fulfil each metric you choose at the same time. As a result, you should clearly analyse how and why the metrics you choose serve your specific objectives. As well as any trade-offs you had to make to safeguard the rights, freedoms and interests of individuals.
Being able to demonstrate why you chose one statistical notion of algorithmic fairness over another can also assist you with your wider accountability obligations.
It is good practice to clearly document your algorithmic fairness objective and the relative disadvantage it is seeking to address.
If you use algorithmic fairness metrics to test your system, you should consider how they account for or interact with broader unfairness risks inherent in the AI lifecycle. For example, the context of your system’s deployment, the groups it impacts, or the input of human reviewers.
Whatever approach you choose, it is important to note that algorithmic fairness metrics do not comprehensively help you to demonstrate that your AI system is fair. This is because of the variety of other factors involved in the entire decision-making process, as well as the often dynamic environment your system operates in. For example, a Live Facial Recognition (LFR) technology system deployed by a private actor in a public space. It processes indiscriminately the personal data of thousands of individuals per day without the necessary safeguards or a DPIA. This is not going to be lawful or fair just because it does not display statistical accuracy variations across groups. Crucially, data protection asks not only how you process personal data but also if you should process it in the first place.
Finally, when you consider your algorithmic fairness approaches, it is also important that you take into account compliance with the Equality Act 2010. This guidance does not cover any of your obligations under equality law. To ensure compliance with equality law, you should refer to guidance produced by the Equality and Human Rights Commission.
Supplementary reading in this guidance
How should we manage competing interests when assessing AI-related risks?
Further reading outside this guidance
A number of toolkits, questionnaires and frameworks have been proposed in order to examine algorithmic fairness and how to negotiate its inherent trade-offs. For more on see ‘Risk identification questionnaire for detecting unintended bias in the machine learning development lifecycle’ and ‘The landscape and gaps in open source fairness toolkits’
What are the limitations of algorithmic fairness approaches?
Algorithmic fairness approaches have several limitations that you should consider when evaluating their efficiency or appropriateness for a specific use case.
- Fairness questions are highly contextual. They often require human deliberation and cannot always be addressed by automated means.
- They are designed to compare between a single category (eg race). As a result, algorithmic fairness metrics may struggle to address issues of intersectional discrimination. This discrimination manifests at the intersection of two or more protected groups without necessarily being visible when comparing pairs of groups one-by-one.
- They may require you to put additional safeguards in place to protect individual rights in accordance with data protection. For example, if you decide to use special category data or protected characteristics to test for algorithmic fairness.
- Some approaches rely on false positives or false negatives. These errors may have different implications for different groups, which influences outcome fairness.
3. Data collection
Take a thoughtful approach to data collection
When you use AI to process personal data, you take decisions about what data to include and why. This applies whether you collect the data from individuals directly, or whether you obtain it from elsewhere.
The purpose limitation and data minimisation principles mean you have to be clear about the personal data you need to achieve your purpose, and only collect that data. Your data should be adequate for your intended purpose.
This also helps to ensure your processing is fair. In the AI context, data is not necessarily an objective interpretation of the world. Depending on the sampling method, datasets tend to mirror a limited aspect of the world and they may reflect outcomes or aspects born out of historical prejudices, stereotypes or inequalities. Awareness of the historical context is crucial for understanding the origin of unfairness in datasets.
This is why you should examine what data you need to collect in relation to your purposes.
Depending on your purpose, you should examine which of the underlying dynamics of the observed environment you want to retain from within the data you have collected, and which you want to dispose of.
To ensure your processing and outcomes are fair, your datasets should be accurate, complete and representative of the purpose of the processing. We have provided guidance on dataset fairness which can assist with your transparency compliance requirements as well. This will also help you to comply with the data minimisation and storage limitation principles, and improve business efficiency.
You should not assume that collecting more data is an effective substitute for collecting better data. Collecting personal data because it is convenient to do so, or because you may find a use for it in the future, does not make that processing fair or lawful. Data protection law requires you to process only the data you need to achieve your stated purpose.
Further reading in ICO guidance
Dataset fairness (Explaining decisions made with AI)
Further reading outside this guidance
For a discussion on methodologies for data collection see ‘Lessons from archives: Strategies for collecting sociocultural data in machine learning’
Assess risks of bias in the data you collect
Bias can arise from different sources. One of these includes the data you originally collect. It is important to carefully assess your datasets instead of just obtaining them from various sources and using them uncritically. This is so you can avoid inadvertently incorporating any underlying unwanted bias they may have.
Therefore, if you obtain datasets from other organisations (eg as a result of a data sharing process), you need to assess the risks of bias in the same way as you would if you collect the data from individuals yourself.
For example, the context in which the data was initially processed may reflect selection (sampling and measurement) biases that are not representative of the population you intend to apply your AI system to.
It is useful to ask your dataset suppliers for information on data collection methodologies and any biases their datasets might have encoded.
You should take into account two main categories of data-driven bias. These are statistical and societal biases. These categories inter-relate so you may find it difficult to consider them separately. Domain expertise can help you identify statistical or societal biases that your datasets may include, and plan your mitigation measures appropriately. In general, identifying the potential sources of bias at an early stage will help you design more effective mitigation approaches.
Later stages of the AI lifecycle may present additional types of bias, such as evaluation bias and emergent bias.
Potential sources of bias across the AI lifecycle:

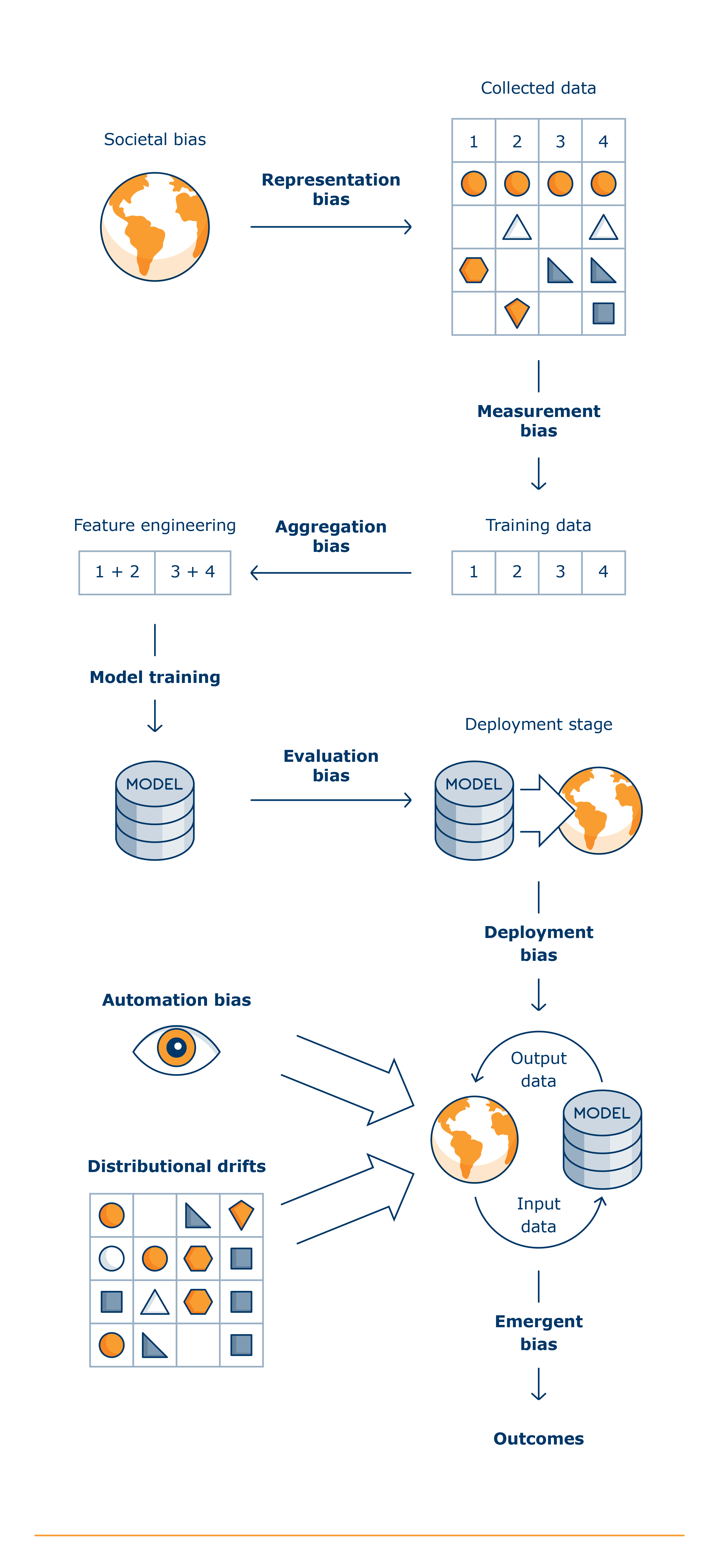
What is statistical bias?
Statistical bias is as an umbrella term for the following:
• Representation or sampling bias. This can occur when your dataset is imbalanced. This means your training dataset is not representative of the population that you will eventually apply your trained model to. Representation bias can result from sampling methods that are inappropriate for the stated purpose, changes in the sampling population or the fact important aspects of the problem are not observed in the training data. For example:
-
- you never get to observe what happens to people whose credit application was denied or fraud cases that were never detected;
- various image datasets used to train computer vision systems have been found to exhibit representation bias; and
- classification systems can perform poorly when encountering cases not present in the training data.


- Measurement bias. This is about the impact of selected features and labels on model performance. It can be caused by differences in the accuracy of the process through which the selected features are measured between groups. For example, attempts to geolocate patterns of fraud could create unintended correlations with particular racial groups. Additionally, depending on the context, the selection of those features and labels may oversimplify the target variable you aim to capture and omit important nuances. For example, if a model predicts the risk of domestic abuse without factoring in an examination or interview of the alleged offenders, the estimated risk may be downplayed or exaggerated.

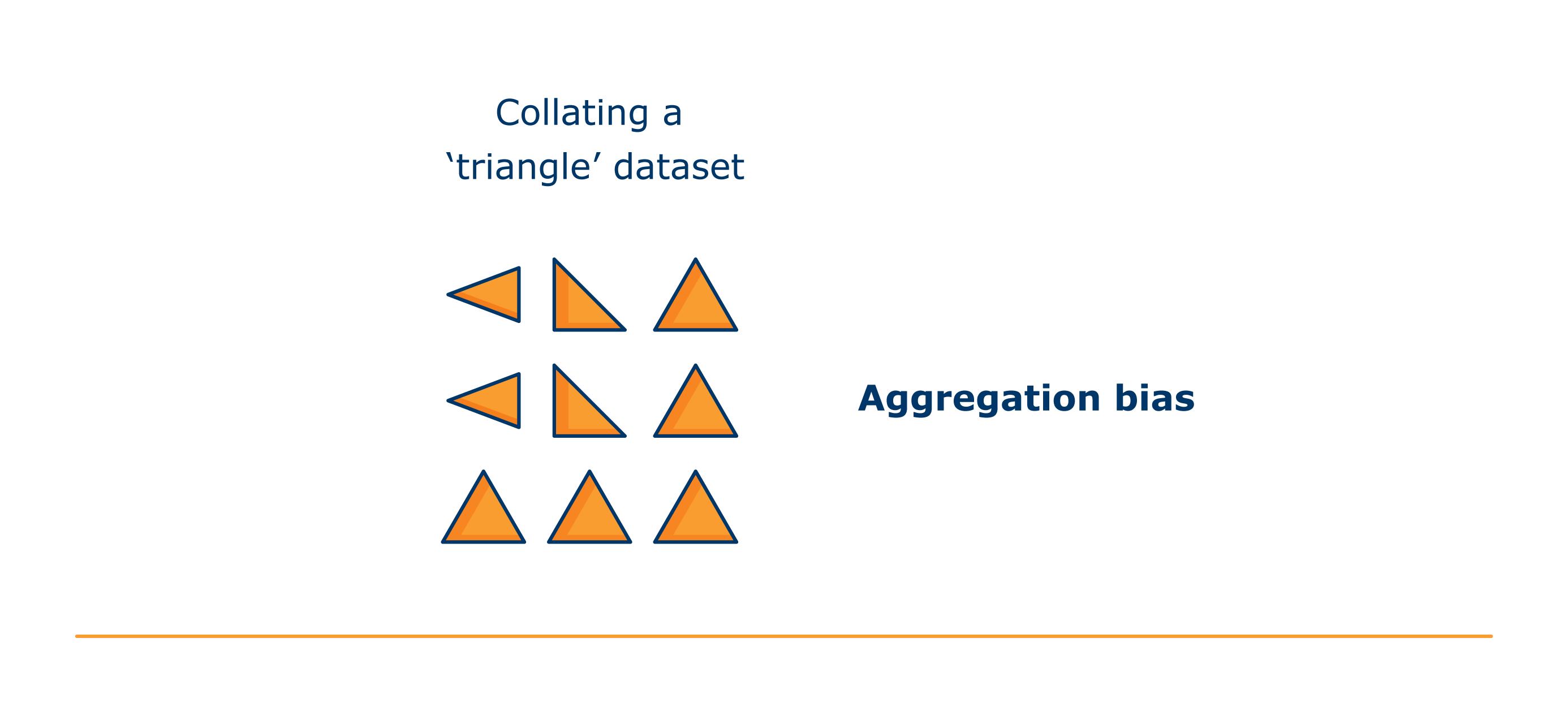
- Aggregation bias. Aggregation bias arises when a one-size-fits-all model is used for data in which there are underlying groups or types of examples that should be considered differently. Aggregation bias can also take place at the feature engineering stage.

Further reading outside this guidance
For more on the sources of bias see ‘A framework for understanding sources of harm throughout the machine learning life cycle’
For more on statistical and societal bias see ‘Algorithmic fairness: choices, assumptions, and definitions’
What is societal bias?
Societal bias is often referred to as historical or structural bias and relates to structural inequalities inherent in society that the data then reflects. In general, predictive AI models are trained to identify patterns in datasets and reproduce them. This means that there is an inherent risk that the models replicate any societal bias in those datasets. For example, if a model uses an engineering degree as a feature, it may replicate pre-existing societal bias arising from the historical level of male representation in that field.
Societal bias can also be institutional or interpersonal. For example, if human recruiters have systematically undermarked individuals from specific backgrounds, an AI system may reflect this bias in its labelling process. In general, it may be particularly risky to deploy AI-driven systems in environments that are known to have significant societal bias.
Consulting domain experts and people with lived experience will enable you to identify societal bias, explore its root causes and design appropriate mitigation measures. For example, consultation in this way may help you identify and mitigate risks resulting from the inappropriate labelling of training data. These can include:
- offering cognitive bias training for these staff members;
- updating your labelling protocol; or
- updating your monitoring process to ensure the protocol is being followed.


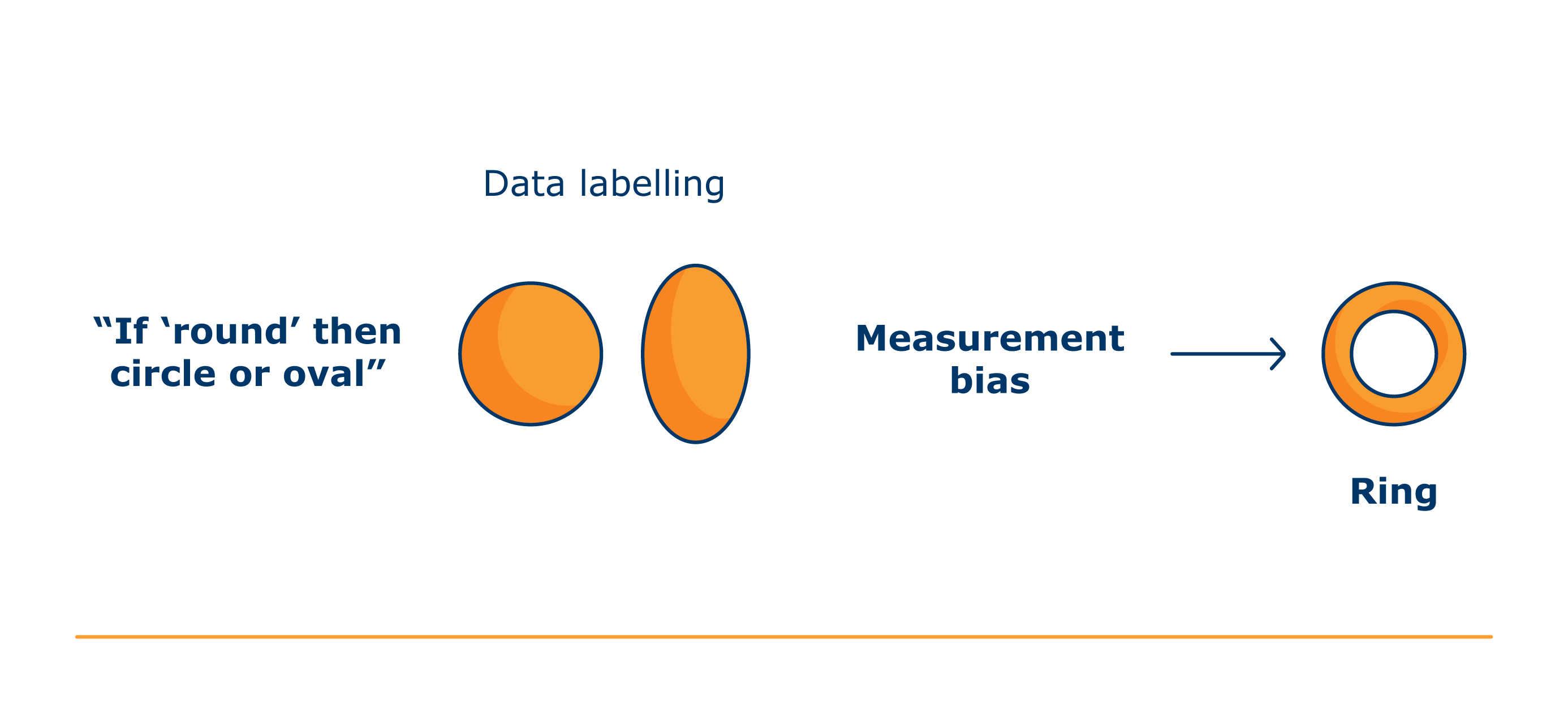
Data labelling
In order to establish a reliable ground truth, it is important that you appropriately annotate your datasets. Having clear criteria for doing this helps you ensure fairness and accuracy during both the acquisition and preparation stages.
Labels can pose fairness risks. This is because they can reflect inaccurate representations of the real world or create an overly-simplistic view of something that is more complex. For example, attempting to label human emotions is unlikely to capture their full complexity, or the context in which they occur. Without mitigation, this could lead to unexpected or unfair impacts in certain use cases (eg emotion recognition systems).
Additionally, misrepresentation or underrepresentation of certain data points can result in risks of harm, such as:
- underrepresentation in labelled data points, leading to harms related to the allocation of opportunities or resources. The impact of allocative decisions may be significant (eg loss of life or livelihood); and
- misrepresentation in labels leading to harms related to the reinforcing of biases or stereotypes. The impact of representative harms could include unfavourable bias for marginalised groups.
Training your staff about implicit bias and how it may impact their decisions is one way of mitigating these risks. Including community groups and impacted individuals in the labelling process is another, and is an example of participatory design in practice. You can then formulate your labelling criteria and protocol as a result.
In general, your training data labels should comply with data protection’s accuracy principle. You should clearly tag output data as inferences and predictions, and not claim it to be factual. You should document clear criteria and lines of accountability for labelling data.
Further reading in this guidance
What do we need to know about accuracy and statistical accuracy?
4. Data analysis and pre-processing
Pre-processing in the AI lifecycle refers to the different processing techniques you apply to the data itself before you feed it into your algorithm. Depending on the circumstances, datasets are likely to be split between training, testing and validation data.
For data protection purposes, it is important to note that “processing” personal data includes the process of collecting that data. This means that processing in the data protection sense begins before the ‘pre-processing’ stage of the AI lifecycle.
If, depending on your context, you need to use bias mitigation techniques using algorithmic fairness metrics, you should track the provenance, development, and use of your training datasets. You should also detect any biases that may be encoded into the personal data you collect or procure. For example, if you sample uniformly from the training dataset, this may result in disparities for minorities that are under-represented within the data. Be mindful that common practices like imputing missing values can introduce biases that may result in unfairness.
To ensure fairness, you may decide not to use certain data sources or features to make decisions about people. For example, when using them may lead to direct or indirect discrimination. In these cases, you should assess, document and record the sources or features that you do not intend to use.
How should we approach bias mitigation at the pre-processing stage?
A number of pre-processing methods, including toolkits and algorithms exist that aim to remove bias from training datasets by altering their statistical properties. That means you need to have access to the training data to use these methods. Also, if you are procuring your model from someone else, you may need to use post-processing techniques as the latter do not require that access. If such techniques are not adequate in your context, you may need to negotiate with your provider to define the terms of your contract. This will ensure measures are in place to adequately address unfairness risks.
You should bear in mind that the efficacy and the limitations of all these algorithmic fairness approaches are an ongoing area of research.
If your collected data reflects societal or statistical bias, you should consider modifying the training data, to remove examples of data that you suspect can lead to discrimination. If your dataset is imbalanced, you may need to collect more data on underrepresented groups. These datasets need to be able to also capture in-group variation to avoid aggregation bias.
Other pre-processing approaches include reweighing your data points or changing your labels. Depending on your selected algorithmic fairness metric, you can change the labels for the groups most likely to be vulnerable to discriminatory patterns.
You should also consider other techniques at the pre-processing stage. For example, data visualisations. These can observe changes in the distribution of key features in order for you to take appropriate actions. Creating histograms and correlations matrices to observe your training data’s distribution patterns and how these change over time can provide insights about potential bias in that dataset.
5. Model development
ML models learn patterns encoded in the training data. They aim to generalise these patterns and apply those generalisations to unseen data. At the model development stage, you are likely to consider and test different algorithms, features and hyperparameters.
We have provided guidance about design fairness, that looks into how you can explain how your design decisions serve fairness goals to individuals.
Model selection
Your choice of model depends on the complexity of your problem and the quantity and quality of the data you have or need to process to address it. You need to consider the balance between your model’s inductive bias and its variance, to ensure it is generalisable and therefore statistically accurate. Variance is the model’s sensitivity to fluctuations in the data, meaning how often it registers noise or trivial features as important.
You should also consider your transparency obligations when selecting your model. For example, in the context of ‘black-box’ models, the lack of access to how a system arrived at a decision may obstruct individuals’ ability to contest one they deem unfair. Additionally, in the case of solely automated decisions with legal or similarly significant effects, being deprived of access to the ‘logic involved’ would mean being deprived of their information rights. This would go against their reasonable expectations.
Further reading in this guidance
Further reading – ICO guidance
Design fairness (Explaining decisions made with AI)
What do you need to consider during feature engineering?
Feature engineering is a core stage in developing your model and transforming data from the original form into features for training your model. This forms part of the process of developing an AI model and involves concepts such as augmentation, aggregation and summarisation of the data. Feature engineering therefore can involve a set of processing operations such as the adaptation or alteration of personal data. This ensures that these new features are more amenable to modelling than the original data.
Feature engineering can mitigate risks of statistical bias, such as aggregation bias. For example, transformation techniques like re-weighting feature values in the training data to reduce the likelihood of discriminatory effects.
However, you should recognise that feature engineering may also introduce risks of statistical bias, specifically aggregation bias. For example, if you do not apply transformation techniques correctly, they could also lead to aggregation bias and therefore not solve the issue you are trying to address. It is therefore important that you carefully assess the impact of the technique to ensure it achieves your desired effect.
Example
Individuals who follow the Catholic, Protestant or Orthodox doctrines are grouped under one “Christian” data feature.
This may fail to account for their distinctions, leading to unexpected results, depending on the context. This is an example of how feature engineering can lead to unfair results.
Feature engineering can also give rise to measurement bias. This can happen when there is a difference in how inputs or target variables are measured between groups. For example, the fractions of the population that have computable records that will be used as features in a model may vary by race. This will affect how accurately those features are measured. For example, that may be the case when specific groups have historically less access to specific services. Deriving unbiased learnings from data collected in the real world is challenging because of unobvious correlations that exist within that data. This nevertheless can impact your model’s performance.
When transforming personal data to create the features, you must consider whether any features are proxies of protected characteristics or special category data. You can establish this through a “proxy analysis”. For example, if your model detects correlations between creditworthiness and correct capitalisation in loan applications, it may penalise people with dyslexia. Once your proxy analysis identifies this, you may be able to remove or adjust the feature to avoid these correlations.
Model optimisation
In ML, model optimisation typically intends to minimise prediction errors. When using algorithmic fairness approaches, you will typically include a fairness metric as another criteria alongside the objective of minimising prediction errors. This is called ‘multi-criteria optimisation’.
You can also intervene in the testing stage, where a held-out sample of the data (the test data) is used to test the generalisability of the model. At this point, it is possible to assign some cost or weight to the underrepresented group to ensure fairness in the prediction.
If you decide to test your model against one of the open source benchmark datasets, you should take into account any biases they contain.
Model design and testing has inherent trade-offs that you need to assess. For example, hyperparameter tuning - the process of identifying the optimal hyperparameters for you model. Different tunings may present distinct trade-offs between statistical accuracy and algorithmic fairness. If you have a clear idea of the context in which you will use your system, then you are better able to assess these trade-offs.
Model optimisation is not straightforward. However, you should consider individuals’ reasonable expectations when you address it. For example:
- there may be implicit assumptions in the decisions you make about the features that are relevant to your problem; and
- how you weigh these features may lead to one or more having a higher importance or prioritisation, and this may not be justifiable to the individuals concerned. For example, job applicants may expect an AI system used for sorting job applications to register recent work experience as of more relevance than a job they held one decade ago and weigh that variable accordingly.
In adaptive models, what you are optimizing for may have downstream consequences for fairness. A reinforcement learning system that explores the relationship of actions and reward functions may lead to unpredictable results when individuals or their personal data inform that learning process. For example, an ad delivery algorithm that is optimised to surface content to people that past data indicates are more likely to click on it. This may set in motion a self-reinforcing feedback loop that entrenches existing inequalities. For example, surfacing ads for computer engineering jobs predominantly to 90% men and 10 % women on the basis that historical data demonstrates that uneven distribution. This is likely to perpetuate and entrench that unequal access to certain professions.
You may need to properly evaluate how to rebalance the current distribution your historical data demonstrates with the optimal or ideal one you are aiming for. It may be useful for your training phase to engage with community groups and impacted individuals. Especially when labelled data is unavailable or when you are dealing with unsupervised ML systems. This could confirm whether the patterns and groupings that are emerging reflect the ground truth as per their knowledge and expectations.
Further reading outside this guidance
For a discussion around key questions AI developers need to ask during training and testing see ‘Hard choices in artificial intelligence: addressing normative uncertainty through sociotechnical commitments’
Overfitting and underfitting
Overfitting is where your model pays too much attention to the details of the training data. Essentially, the model remembers particular examples