At a glance
This section explains the challenges to ensure individual rights in AI systems, including rights relating to solely automated decision-making with legal or similarly significant effect. It also covers the role of meaningful human oversight.
Who is this section for?
This section is aimed at those in compliance-focused roles who are responsible for responding to individual rights requests. The section makes reference to some technical terms and measures, which may require input from a technical specialist.
In detail
- How do individual rights apply to different stages of the AI lifecycle?
- How do individual rights relate to data contained in the model itself?
- How do we ensure individual rights relating to solely automated decisions with legal or similar effect?
- What is the role of human oversight?
How do individual rights apply to different stages of the AI lifecycle?
Under data protection law individuals have a number of rights relating to their personal data. Within AI, these rights apply wherever personal data is used at any of the various points in the development and deployment lifecycle of an AI system. This therefore covers personal data:
- contained in the training data;
- used to make a prediction during deployment, and the result of the prediction itself; or
- that might be contained in the model itself.
This section describes what you may need to consider when developing and deploying AI and complying with the individual rights of information, access, rectification, erasure, and to restriction of processing, data portability, and objection (rights referred to in Articles 13-21 of the UK GDPR). It does not cover each right in detail but discusses general challenges to complying with these rights in an AI context, and where appropriate, mentions challenges to specific rights.
Rights that individuals have about solely automated decisions that affect them in legal or similarly significant ways are discussed in more detail in ‘What is the role of human oversight?’, as these rights raise particular challenges when using AI.
How should we ensure individual rights requests for training data?
When creating or using ML models, you invariably need to obtain data to train those models.
For example, a retailer creating a model to predict consumer purchases based on past transactions needs a large dataset of customer transactions to train the model on.
Identifying the individuals that the training data is about is a potential challenge to ensuring their rights. Typically, training data only includes information relevant to predictions, such as past transactions, demographics, or location, but not contact details or unique customer identifiers. Training data is also typically subjected to various measures to make it more amenable to ML algorithms. For example, a detailed timeline of a customer’s purchases might be transformed into a summary of peaks and troughs in their transaction history.
This process of transforming data prior to using it for training a statistical model, (for example, transforming numbers into values between 0 and 1) is often referred to as ‘pre-processing’. This can create confusion about terminology in data protection, where ‘processing’ refers to any operation or set of operations which is performed on personal data. So ‘pre-processing’ (in machine learning terminology) is still ‘processing’ (in data protection terminology) and therefore data protection still applies.
Because these processes involve converting personal data from one form into another potentially less detailed form, they may make training data potentially much harder to link to a particular named individual. However, in data protection law this is not necessarily considered sufficient to take that data out of scope. You therefore still need to consider this data when you are responding to individuals’ requests to exercise their rights.
Even if the data lacks associated identifiers or contact details, and has been transformed through pre-processing, training data may still be considered personal data. This is because it can be used to ‘single out’ the individual it relates to, on its own or in combination with other data you may process (even if it cannot be associated with a customer’s name).
For example, the training data in a purchase prediction model might include a pattern of purchases unique to one customer.
In this example, if a customer provided a list of their recent purchases as part of their request, the organisation may be able to identify the portion of the training data that relates to them.
In these kinds of circumstances, you are obliged to respond to an individual’s request, assuming you have taken reasonable measures to verify their identity and no other exceptions apply.
There may be times where you are not able to identify an individual in the training data, directly or indirectly. Provided you are able to demonstrate this, individual rights under Articles 15 to 20 do not apply. However, if the individual provides additional information that enables identification, this is no longer the case and you need to fulfil any request they make. You should consult our guidance on determining what is personal data for more information about identifiability.
We recognise that the use of personal data with AI may sometimes make it harder to fulfil individual rights to information, access, rectification, erasure, restriction of processing, and notification. If a request is manifestly unfounded or excessive, you may be able to charge a fee or refuse to act on the request. However, you should not regard requests about such data as manifestly unfounded or excessive just because they may be harder to fulfil in the context of AI or the motivation for requesting them may be unclear in comparison to other access requests you might typically receive.
If you outsource an AI service to another organisation, this could also make the process of responding to rights requests more complicated when the personal data involved is processed by them rather than you. When procuring an AI service, you must choose one which allows individual rights to be protected and enabled, in order to meet your obligations as a controller. If your chosen service is not designed to easily comply with these rights, this does not remove or change those obligations. If you are operating as a controller, your contract with the processor must stipulate that the processor assist you in responding to rights requests. If you are operating an AI service as a joint controller, you need to decide with your fellow controller(s) who will carry out which obligations. See the section ‘How should we understand controller/processor relationships in AI?’ for more details.
In addition to these considerations about training data and individual rights in general, below we outline some considerations about how particular individual rights (rectification, erasure, portability, and information) may relate to training data.
- Right to rectification
The right to rectification may apply to the use of personal data to train an AI system. The steps you should take for rectification depend on the data you process as well as the nature, scope, context and purpose of that processing. The more important it is that the personal data is accurate, the greater the effort you should put into checking its accuracy and, if necessary, taking steps to rectify it.
In the case of training data for an AI system, one purpose of the processing may be to find general patterns in large datasets. In this context, individual inaccuracies in training data may be less important, as they are not likely to affect the performance of the model, since they are just one data point among many, when compared to personal data that you might use to take action about an individual.
For example, you may think it more important to rectify an incorrectly recorded customer delivery address than to rectify the same incorrect address in training data. Your rationale is likely to be that the former could result in a failed delivery, but the latter would barely affect the overall statistical accuracy of the model.
However, in practice, the right of rectification does not allow you to disregard any requests because you think they are less important for your purposes.
- Right to erasure
You may also receive requests for the erasure of personal data contained within training data. You should note that whilst the right to erasure is not absolute, you still need to consider any erasure request you receive, unless you are processing the data on the basis of a legal obligation or public task (both of which are unlikely to be lawful bases for training AI systems – see the section on lawful bases for more information).
The erasure of one individual’s personal data from the training data is unlikely to affect your ability to fulfil the purposes of training an AI system (as you are likely to still have sufficient data from other individuals). You are therefore unlikely to have a justification for not fulfilling the request to erase their personal data from your training dataset.
Complying with a request to erase training data does not entail erasing all ML models based on this data, unless the models themselves contain that data or can be used to infer it (situations which we will cover in the section below).
- Right to data portability
Individuals have the right to data portability for data they have ‘provided’ to a controller, where the lawful basis of processing is consent or contract. ‘Provided data’ includes data the individual has consciously input into a form, but also behavioural or observational data gathered in the process of using a service.
In most cases, data used for training a model (eg demographic information or spending habits) counts as data ‘provided’ by the individual. The right to data portability therefore applies in cases where this processing is based on consent or contract.
However, as discussed above, pre-processing methods are usually applied which significantly change the data from its original form into something that can be more effectively analysed by machine learning algorithms. Where this transformation is significant, the resulting data may no longer count as ‘provided’.
In this case the data is not subject to data portability, although it does still constitute personal data and as such other data protection rights still apply (eg the right of access). However, the original form of the data from which the pre-processed data was derived is still subject to the right to data portability (if provided by the individual under consent or contract and processed by automated means).
- Right to be informed
You must inform individuals if their personal data is going to be used to train an AI system, to ensure that processing is fair and transparent. You should provide this information at the point of collection. If the data was initially processed for a different purpose, and you later decide to use it for the separate purpose of training an AI system, you need to inform the individuals concerned (as well as ensuring the new purpose is compatible with the previous one). In some cases, you may not have obtained the training data from the individual, and therefore not have had the opportunity to inform them at the time you did so. In such cases, you should provide the individual with the information specified in Article 14 within a reasonable period, one month at the latest, unless a relevant exemption from Article 14(5) applies.
Since using an individual’s data for the purposes of training an AI system does not normally constitute making a solely automated decision with legal or similarly significant effects, you only need to provide information about these decisions when you are taking them. However, you still need to comply with the main transparency requirements.
For the reasons stated above, it may be difficult to identify and communicate with the individuals whose personal data is contained in the training data. For example, training data may have been stripped of any personal identifiers and contact addresses (while still remaining personal data). In such cases, it may be impossible or involve a disproportionate effort to provide information directly to the individual.
Therefore, instead you should take appropriate measures to protect the individual’s rights and freedoms and legitimate interests. For example, you could provide public information explaining where you obtained the data from that you use to train your AI system, and how to object.
How should we ensure individual rights requests for AI outputs?
Typically, once deployed, the outputs of an AI system are stored in a profile of an individual and used to take some action about them.
For example, the product offers a customer sees on a website might be driven by the output of the predictive model stored in their profile. Where this data constitutes personal data, it will generally be subject to all of the rights mentioned above (unless exemptions or other limitations to those rights apply).
Whereas individual inaccuracies in training data may have a negligible effect, an inaccurate output of a model could directly affect the individual. Requests for rectification of model outputs (or the personal data inputs on which they are based) are therefore more likely to be made than requests for rectification of training data. However, as said above, predictions are not inaccurate if they are intended as prediction scores as opposed to statements of fact. If the personal data is not inaccurate then the right to rectification does not apply.
Personal data resulting from further analysis of provided data is not subject to the right to portability. This means that the outputs of AI models such as predictions and classifications about individuals are out of scope of the right to portability.
In some cases, some or all of the features used to train the model may themselves be the result of some previous analysis of personal data. For example, a credit score which is itself the result of statistical analysis based on an individual’s financial data might then be used as a feature in an ML model. In these cases, the credit score is not included within scope of the right to data portability, even if other features are.
Further reading outside this guidance
Read our guidance on individual rights, including:
- the right to be informed;
- the right of access;
- the right to erasure;
- the right to rectification; and
- the right to data portability.
How do individual rights relate to data contained in the model itself?
In addition to being used in the inputs and outputs of a model, in some cases personal data might also be contained in a model itself. As explained in ’what types of privacy attacks apply to AI models?’, this could happen for two reasons; by design or by accident.
How should we fulfil requests about models that contain data by design?
When personal data is included in models by design, it is because certain types of models, such as Support Vector Machines (SVMs), contain some key examples from the training data in order to help distinguish between new examples during deployment. In these cases, a small set of individual examples are contained somewhere in the internal logic of the model.
The training set typically contains hundreds of thousands of examples, and only a very small percentage of them end up being used directly in the model. Therefore, the chances that one of the relevant individuals makes a request are very small; but remains possible.
Depending on the particular programming library in which the ML model is implemented, there may be a built-in function to easily retrieve these examples. In these cases, it is likely to be practically possible for you to respond to an individual’s request. To enable this, where you are using models which contain personal data by design, you should implement them in a way that allows the easy retrieval of these examples.
If the request is for access to the data, you could fulfil this without altering the model. If the request is for rectification or erasure of the data, this may not be possible without re-training the model (either with the rectified data, or without the erased data), or deleting the model altogether.
While it is not a legal requirement, having a well-organised model management system and deployment pipeline will make it easier and cheaper to accommodate these requests, and re-training and redeploying your AI models accordingly will be less costly.
How should we fulfil requests about data contained in models by accident?
Aside from SVMs and other models that contain examples from the training data by design, some models might ‘leak’ personal data by accident. In these cases, unauthorised parties may be able to recover elements of the training data, or infer who was in it, by analysing the way the model behaves.
The rights of access, rectification, and erasure may be difficult or impossible to exercise and fulfil in these scenarios. Unless the individual presents evidence that their personal data could be inferred from the model, you may not be able to determine whether personal data can be inferred and therefore whether the request has any basis.
You should regularly and proactively evaluate the possibility of personal data being inferred from models in light of the state-of-the-art technology, so that you minimise the risk of accidental disclosure.
How do we ensure individual rights relating to solely automated decisions with legal or similar effect?
There are specific provisions in data protection law covering individuals’ rights where processing involves solely automated individual decision-making, including profiling, with legal or similarly significant effects. These provisions cover both information you have to provide proactively about the processing and individuals’ rights in relation to a decision made about them.
Under Articles 13 (2)(f) and 14 (2)(g), you must tell people whose data you are processing that you are doing so for automated decision-making and give them “meaningful information about the logic involved, as well as the significance and the envisaged consequences” of the processing for them. Under Article 15 (2)(h) you must also tell them about this if they submit a subject access request.
In addition, data protection requires you to implement suitable safeguards when processing personal data to make solely automated decisions that have a legal or similarly significant impact on individuals. These safeguards include the right for individuals to:
- obtain human intervention;
- express their point of view;
- contest the decision made about them; and
- obtain an explanation about the logic of the decision.
For processing involving solely automated decision-making that falls under Part 2 of the DPA 2018, these safeguards differ to those in the UK GDPR if the lawful basis for that processing is a requirement or authorisation by law.
For processing involving solely automated decision-making that falls under Part 3 of the DPA 2018, the applicable safeguards will depend on regulations provided in the particular law authorising the automated decision-making. Although the individual has the right to request that you reconsider the decision or take a new decision that is not based solely on automated processing.
These safeguards cannot be token gestures. Human intervention should involve a review of the decision, which must be carried out by someone with the appropriate authority and capability to change that decision. That person’s review should also include an assessment of all relevant data, including any information an individual may provide.
The conditions under which human intervention qualifies as meaningful are similar to which render a decision non-solely automated (see ‘What is the difference between solely automated and partly automated decision-making?’ below). However, a key difference is that in solely automated contexts, human intervention is only required on a case-by-case basis to safeguard the individual’s rights, whereas for a system to qualify as not solely automated, meaningful human intervention is required in every decision.
Note that if you are using automated decision making, as well as implementing suitable safeguards, you must also have a suitable lawful basis. See ‘How do we identify our purposes and lawful basis when using AI?’ and ‘What is the impact of Article 22 of the UK GDPR?’ above.
Further reading outside this guidance
See the ICO and The Alan Turing guidance on ‘Explaining decisions made with Artificial Intelligence’
See our guidance on rights related to automated decision-making including profiling
Also see our in-depth guidance on rights related to automated decision-making including profiling
Further reading – European Data Protection Board
The European Data Protection Board (EDPB), which has replaced the Article 29 Working Party (WP29), includes representatives from the data protection authorities of each EU member state. It adopts guidelines for complying with the requirements of the EU version of the GDPR.
EDPB guidelines are no longer directly relevant to the UK regime and are not binding under the UK regime. However, they may still provide helpful guidance on certain issues.
Why could rights relating to automated decisions be a particular issue for AI systems?
The type and complexity of the systems involved in making solely automated decisions affect the nature and severity of the risk to people’s data protection rights and raise different considerations, as well as compliance and risk management challenges.
Firstly, transparency issues arise because of complex algorithms, such as neural networks or complex software supply chains. Frictionless design such as ambient intelligence can exacerbate this challenge. A ‘smart’ home device that decides what job advert to serve depending on the content of an individual’s speech may not enable that individual to understand a decision is being made about them. However, irrespective of the type of AI system you use, if it processes personal data you need to comply with data protection law.
Basic systems, which automate a relatively small number of explicitly written rules, are unlikely to be considered AI (eg a set of clearly expressed ‘if-then’ rules to determine a customer’s eligibility for a product). However, the resulting decisions could still constitute automated decision-making within the meaning of data protection law.
It should also be relatively easy for a human reviewer to identify and rectify any mistake, if a decision is challenged by an individual because of a system’s high interpretability.
However other systems, such as those based on ML, may be more complex and present more challenges for meaningful human review. ML systems make predictions or classifications about people based on data patterns. Even when they are highly statistically accurate, they will occasionally reach the wrong decision in an individual case. Errors may not be easy for a human reviewer to identify, understand or fix.
While not every challenge from an individual will result in the decision being overturned, you should expect that many could be. There are two particular reasons why this may be the case in ML systems:
- the individual is an ‘outlier’, ie their circumstances are substantially different from those considered in the training data used to build the AI system. Because the ML model has not been trained on enough data about similar individuals, it can make incorrect predictions or classifications; or
- assumptions in the AI design can be challenged, eg a continuous variable such as age, might have been broken up (‘binned’) into discrete age ranges, like 20-39, as part of the modelling process. Finer-grained ‘bins’ may result in a different model with substantially different predictions for people of different ages. The validity of this data pre-processing and other design choices may only come into question as a result of an individual’s challenge.
What steps should we take to fulfil rights related to automated decision-making?
You should:
- consider the system requirements necessary to support a meaningful human review from the design phase. Particularly, the interpretability requirements and effective user-interface design to support human reviews and interventions;
- design and deliver appropriate training and support for human reviewers; and
- give staff the appropriate authority, incentives and support to address or escalate individuals’ concerns and, if necessary, override the AI system’s decision.
However, there are some additional requirements and considerations you should be aware of.
The ICO’s and the Alan Turing Institute’s ‘Explaining decisions made with AI’ guidance looks at how, and to what extent, complex AI systems might affect your ability to provide meaningful explanations to individuals. However, complex AI systems can also impact the effectiveness of other mandatory safeguards. If a system is too complex to explain, it may also be too complex to meaningfully contest, intervene on, review, or put an alternative point of view against.
For example, if an AI system uses hundreds of features and a complex, non-linear model to make a prediction, then it may be difficult for an individual to determine which variables or correlations to object to. Therefore, safeguards around solely automated AI systems are mutually supportive, and should be designed holistically and with the individual in mind.
The information about the logic of a system and explanations of decisions should give individuals the necessary context to decide whether, and on what grounds, they would like to request human intervention. In some cases, insufficient explanations may prompt individuals to resort to other rights unnecessarily. Requests for intervention, expression of views, or contests are more likely to happen if individuals don’t feel they have a sufficient understanding of how the decision was reached.
Transparency measures do not just relate to your model’s internal logic but also to the constraints in which it operates. For example, it may be useful for an individual to know whether a gender classifier only uses binary variables, or what options it considers. This is because they may find being deprived of certain outcomes such as a non-binary label against their reasonable expectations and therefore the processing unfair.
It is good practice to communicate the inherent uncertainty of AI-driven decision-making and predictions. This helps individuals and groups evaluate the predictions your system makes and enables them to challenge any decisions that result.
For example, if loan applicants know the confidence interval that indicates the reliability of an inference, it could help those whose applications are rejected to more effectively challenge the decision.
It is also good practice for you to communicate different levels of uncertainty about the data sources involved in your decision-making process, as well as any potential biases in the data itself.
The process for individuals to exercise their rights should be simple and user friendly. For example, if you communicate the result of the solely automated decision through a website, the page should contain a link or clear information allowing the individual to contact a member of staff who can intervene, without any undue delays or complications.
You are also required to keep a record of all decisions made by an AI system as part of your accountability and documentation obligations. This should also include whether an individual requested human intervention, expressed any views, contested the decision, and whether you changed the decision as a result.
You should monitor and analyse this data. If decisions are regularly changed in response to individuals exercising their rights, you should then consider how you will amend your systems accordingly. Where your system is based on ML, this might involve including the corrected decisions into fresh training data, so that similar mistakes are less likely to happen in future.
More substantially, you may identify a need to collect more or better training data to fill in the gaps that led to the erroneous decision, or modify the model-building process (ie by changing the feature selection).
In addition to being a compliance requirement, this is also an opportunity for you to improve the performance of your AI systems and, in turn, build individuals’ trust in them. However, if grave or frequent mistakes are identified, you need to take immediate steps to understand and rectify the underlying issues and, if necessary, suspend the use of the automated system.
There are also trade-offs that having a human-in-the-loop may entail. Either in terms of a further erosion of privacy, if human reviewers need to consider additional personal data in order to validate or reject an AI generated output, or the possible reintroduction of human biases at the end of an automated process.
Further reading outside this guidance
Read our guidance on Documentation
European guidelines on automated decision-making and profiling.
ICO and The Alan Turing Institute guidance on ‘Explaining decisions made with artificial intelligence’.
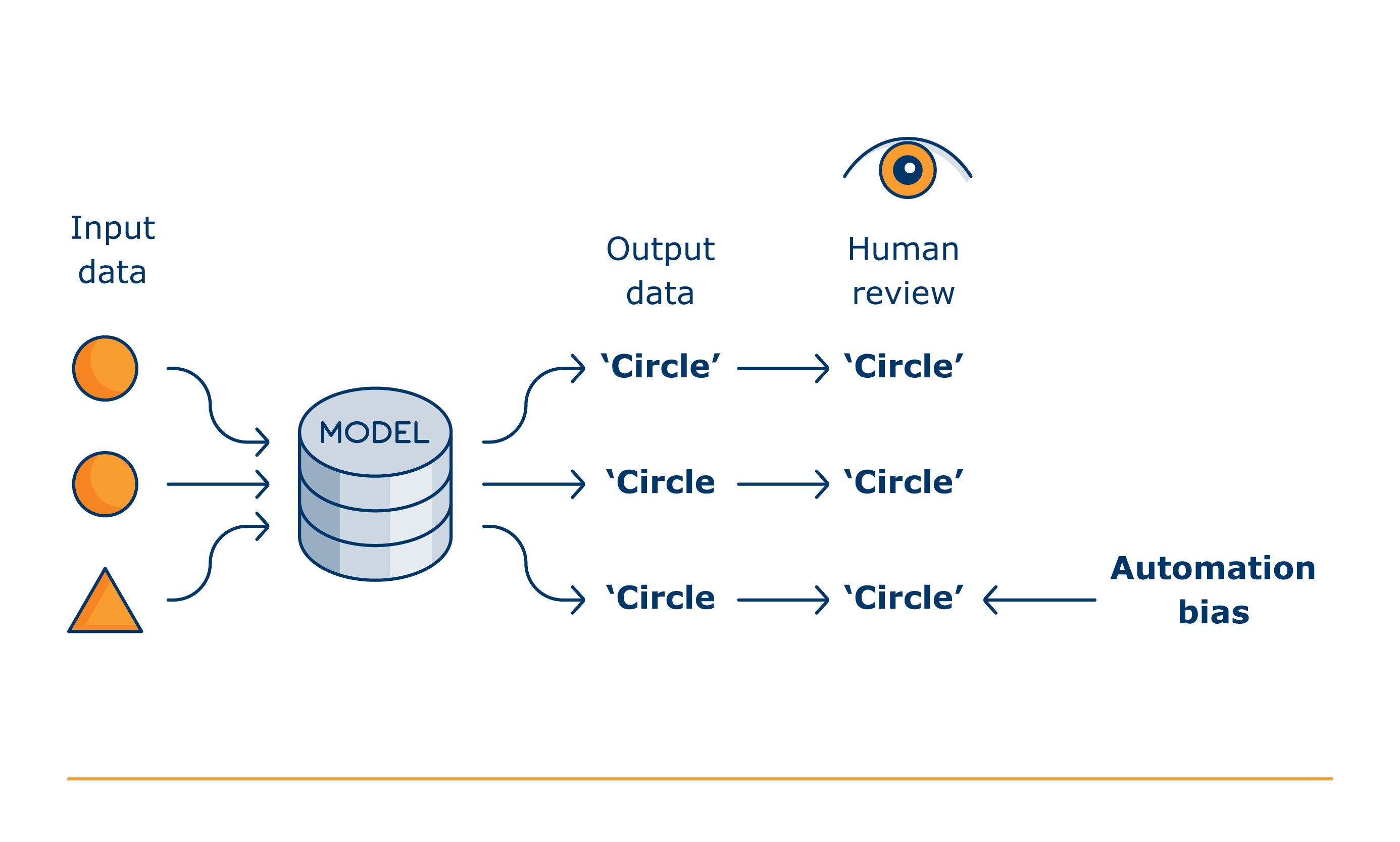
What is the role of human oversight?
When AI is used to inform legal or similarly significant decisions about individuals, there is a risk that these decisions are made without appropriate human oversight. For example, whether they have access to financial products or job opportunities. This infringes Article 22 of the UK GDPR.
To mitigate this risk, you should ensure that people assigned to provide human oversight remain engaged, critical and able to challenge the system’s outputs wherever appropriate.
What is the difference between solely automated and partly automated decision-making?
You can use AI systems in two ways:
- for automated decision-making (ADM), where the system makes a decision automatically; or
- as decision-support, where the system only supports a human decision-maker in their deliberation.
For example, you could use AI in a system which automatically approves or rejects a financial loan, or merely to provide additional information to support a loan officer when deciding whether to grant a loan application.
Whether solely automated decision-making is generally more or less risky than partly automated decision-making depends on the specific circumstances. You therefore need to evaluate this based on your own context.
Regardless of their relative merits, automated decisions are treated differently to human decisions in data protection law. Specifically, Article 22 of the UK GDPR restricts fully automated decisions which have legal or similarly significant effects on individuals to a more limited set of lawful bases and requires certain safeguards to be in place.
By contrast, the use of decision-support tools are not subject to these conditions. However, the human input needs to be meaningful. You should be aware that a decision does not fall outside the scope of Article 22 just because a human has ‘rubber-stamped’ it. The degree and quality of human review and intervention before a final decision is made about an individual are key factors in determining whether an AI system is being used for automated decision-making or merely as decision-support.
Ensuring human input is meaningful in these situations is not just the responsibility of the human using the system. Senior leaders, data scientists, business owners, and those with oversight functions if you have them, among others, are expected to play an active role in ensuring that AI applications are designed, built, and used as intended.
If you are deploying AI systems which are designed as decision-support tools, and therefore are intended to be outside the scope of Article 22, you should be aware of existing guidance on these issues from both the ICO and the EDPB.
The key considerations are:
- human reviewers must be involved in checking the system’s recommendation and should not just apply the automated recommendation to an individual in a routine fashion;
- reviewers’ involvement must be active and not just a token gesture. They should have actual ‘meaningful’ influence on the decision, including the ‘authority and competence’ to go against the recommendation; and
- reviewers must ‘weigh-up’ and ‘interpret’ the recommendation, consider all available input data, and also take into account other additional factors.